2025Kaggler Shanghai Meetup笔记
子午量化主办。
日本kaggler社区文化与职场文化
From senkin13(GM,最高天梯14)
pass
迈向更高效的大型推理模型:AIMO2方案总结与Fast-Math模型介绍
From analokamus(GM,最高天梯66)
中日混血。东京大学公共医学专业。
“AI Mathematical Olympiad - Progress Prize 2”第9名
挑战
挑战一:问题变得更困难了
AIMO1 1st model: 2/50(29/50 at AIMO1)
Qwen2.5-Math-72B-CoT: 5/50
Qwen2.5-Math-72B-TIR( tool-integrated reasoning): 8/50
随着比赛的进行,长推理模型的推出,这一问题得到改善。
QwQ-32B-Preview: 18/50
R1-Distilled-Qwen-14B: 27/50
最好的公开笔记本:Qwen-7B-AWQ on vLLM,early stop at </think> token
挑战二:推理容量
(1)加强CoT的容量
(2)使用TIR
让模型输出code,而不是直接出答案。
挑战三:推理效率
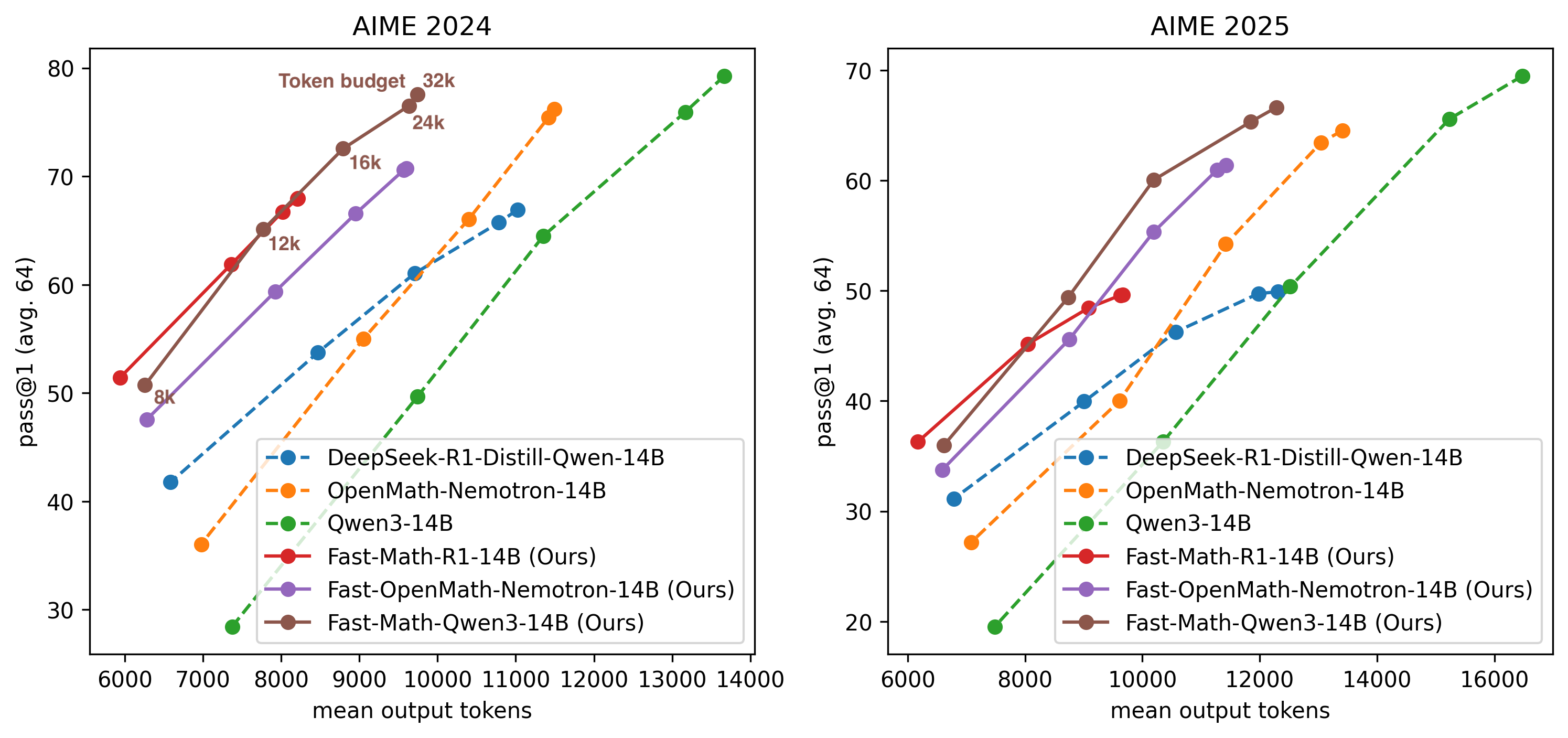 。
。
提高推理效率:《Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs》
量化,使用更好的硬件等。
第二名解决方案
清华大学团队。
一、完善推理
阶段1:SFT
选择 DeepSeek-R1-Distill-Qwen-14B 作为基础模型,因为它在数学、编码和推理方面表现出色。
将 Light-R1 的 stage2 数据和 Limo 的训练数据结合起来(去重),这些数据都是由deepseek-r1 生成的高难度数学问题的推理路径
在单台 8×A800 机器上对基础模型进行 8 个 epoch 的微调,耗时 11 小时。
阶段2:DPO
使用DPO来减少模型的输出长度
选择默认的子集OpenR1-Math-220k来构建的数据集
具体地,尝试使用以下四个标准来构造DPO对(y_w, y_l表示选择的响应和拒绝的响应):
- 正确性:y_w必须正确,y_l可能是正确的或不正确
- 长度比:len(y_w) < ratio_threshold * len(y_l)
- 最小长度: len(y_w) > min_threshold
- 相似性:sim(y_w,y_l) < sim_threshold
二、效率优化
选择 lmdeploy 作为LLM推理框架。与 vllm相比,使用 lmdeploy 框架和TurboMind引擎可以提供更高的吞吐量和更短的模型初始化时间。
量化
应用了4位AWQ权重量化和8位KV缓存量化(将配置设置为8以使用由main_model.inference_cfg.quant_policy 实现的8位KV缓存量化lmdeploy)。
三、推理时间策略
整体推理工作流程
推理工作流程如下面的图所示:提供一个问题作为输入。首先准备两种类型的提示,包括CoT提示和Code提示(“提示准备任务”)。然后,让LLM开始对多个样本进行批处理生成(“LLM生成任务”)。同时,不断尝试从每个样本的流式输出中提取答案,聚合多个样本的答案,并判断是否提前停止某些生成。lmdeploy
- 对通过
stream_infer(...)调用获得的迭代器的每N次生成进行样本级检查,并判断是否提前停止相应样本的生成。这里使用了Python代码执行器和答案提取器组件。 - 在每个样本结束时进行题目的逐个检查,并判断是否提前停止当前问题的所有剩余样本的生成。这里使用了答案聚合组件。
最后,返回聚合后的答案。
注意,对于每个问题,根据剩余时间调整与速度相关的超参数(样本数量、采样级别最大时间、题目级别提前停止标准),这样当剩余时间有限时,可以更均衡地分配时间配额用于剩余的问题。
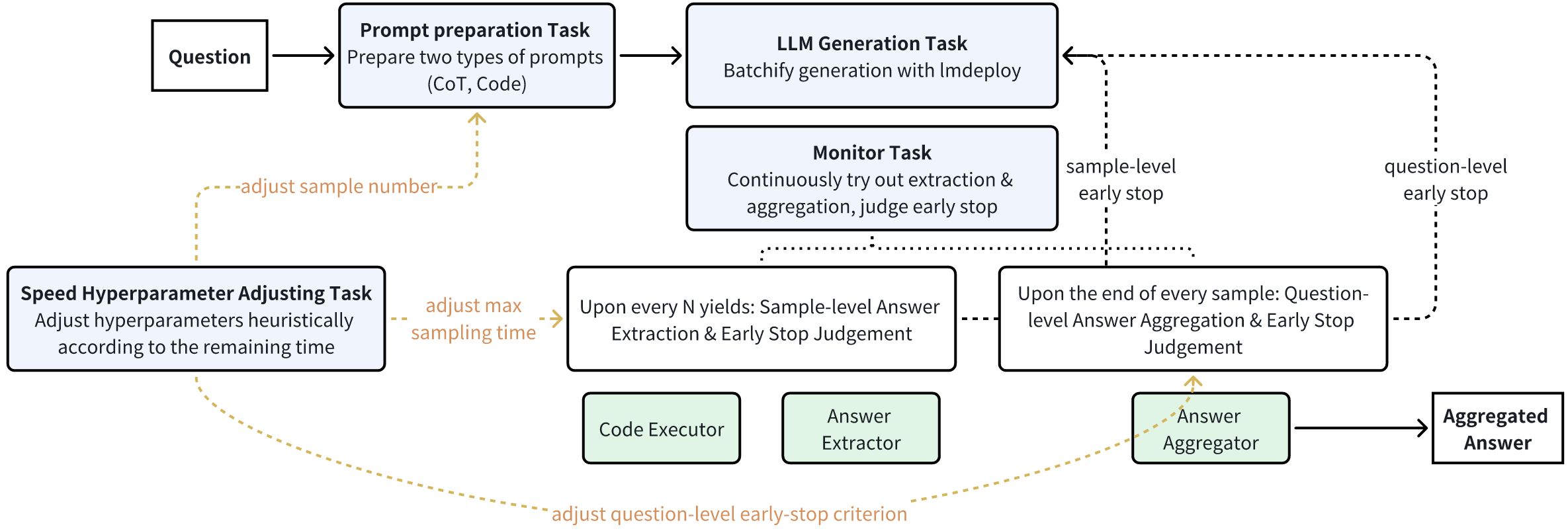
使用两种类型的提示:一个CoT提示和一个代码提示。在15个样本中,7个样本使用CoT提示,8个样本使用代码提示:
1 | |
早期停止
动机:通常,推理模型在提前获得答案后会自我怀疑很多,即使最终通常会给出相同的答案。而且在大多数情况下,在给出答案之间<think></think>,模型会重新编写解决方案(至少两次)。
方法:尽管作者尝试了“Fu 等人,”Efficiently Serving LLM Reasoning Programs with Certaindex, arXiv 2412”中的主动探查方法,但最终采用了更简单的样本级早期停止技术来简化推理工作流程。具体来说,一旦检测到第一个成功可执行的代码或第一个在“\boxed{…}”中的答案,就停止该样本的生成过程。
竞猜小游戏
From hyd/ethan
kaggle lmsys冠军方案与大模型比赛tips
From sayoulala(GM,最高天梯9)
kaggle量化比赛的发展与总结
From rib~(GM,最高天梯20)
从竞赛中挖掘idea并发表两篇顶会
From max2020(GM,最高天梯69)
浙大Phd。20年加入kaggle和开始读博。目前做金融风控。
拍拍贷举办的比赛,任务介绍:图数据集。预测逾期。
对图进行增广。使用分箱进一步提取特征。
思考: LGB+特征工程>GNN,GNN为什么失败?
第一篇论文 DGA-GNN
第二篇论文
推荐比赛如何获得第三名
From sirius(Master,最高天梯149)
H&M Personalized Fashion Recommendations
solo第三
非科班如何打好Kaggle:个人经验与建议
From heng(GM,最高天梯43)
机电工程师,系统工程师。非科班。
找准发力点,不断复盘
设备: 图吧垃圾佬PC机。公网IP+jupyter+frp内网穿透。3090整机。
COZE agent来抓取页面。 豆包多智能市场可搜到。
claude适合baseline,deepseek适合优化。
AI与虚拟细胞
From horikitasaku(Expert)
大四学生,即将成为博士生。
题外话
希望下次能通过比赛拿到入场券。