JustRL: Scaling a 1.5B LLM with a Simple RL Recipe
(arxiv 2025)
清华大学、伊利诺伊大学厄巴纳-香槟分校和上海人工智能实验室出品。
背景
在训练更小、轻量级的模型时,业界普遍认为 RL 训练不稳定,因此倾向于使用知识蒸馏。
为了稳定 RL 训练,许多研究引入了多阶段训练、动态超参数调度、课程学习、奖励长度惩罚等复杂“技巧” 。
但是这些复杂性真的是必要的吗?还是它们只是在解决由其他复杂设置引入的问题?
本篇论文探讨是否可以通过更简单的方法实现稳定且具有竞争力的训练。
极简方法
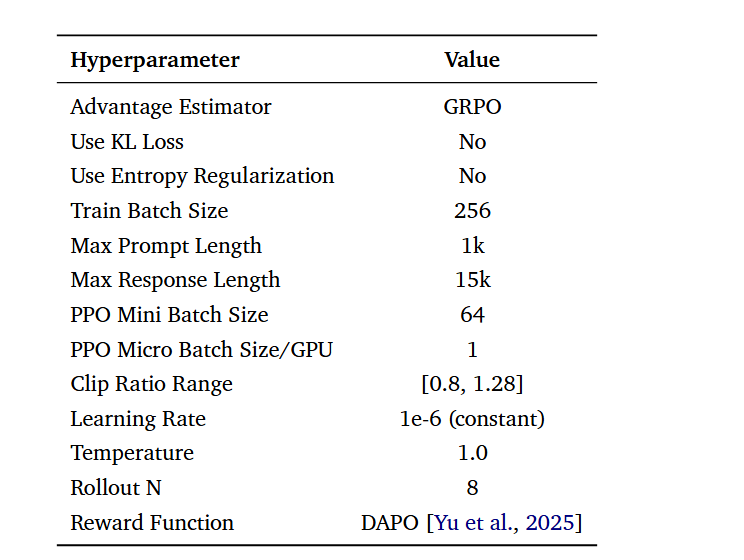
单阶段训练: 不分阶段,没有上下文长度的逐步增加,从头到尾持续训练。
固定超参数: 学习率($1 \times 10^{-6}$)、温度(1.0)等始终保持恒定,不进行动态调整。
标准数据与提示: 使用公开的 DAPO-Math-17k 数据集,配合简单的后缀提示:“Please reason step by step, and put your final answer within \boxed{}.”
简单的长度控制: 仅设置 16K 的最大上下文长度,不使用显式的长度惩罚项。
核心算法: 使用 veRL 框架中的 GRPO 算法,配合基于规则的简单验证器。
唯一使用的技术是clip higher。这是一种在长时域强化学习训练中提高稳定性的成熟做法。
在标准的 PPO(近端策略优化)或 GRPO 算法中,为了防止策略更新过快导致崩溃,通常会对新旧策略的比率 $r_t(\theta)$ 进行对称裁剪,范围通常是 $[1-\epsilon, 1+\epsilon]$(例如 $[0.8, 1.2]$)。
而 “clip higher” 指的是调高裁剪范围的上界。在 JustRL 中,其 Clip Ratio Range 为 [0.8, 1.28] 。
实验结果
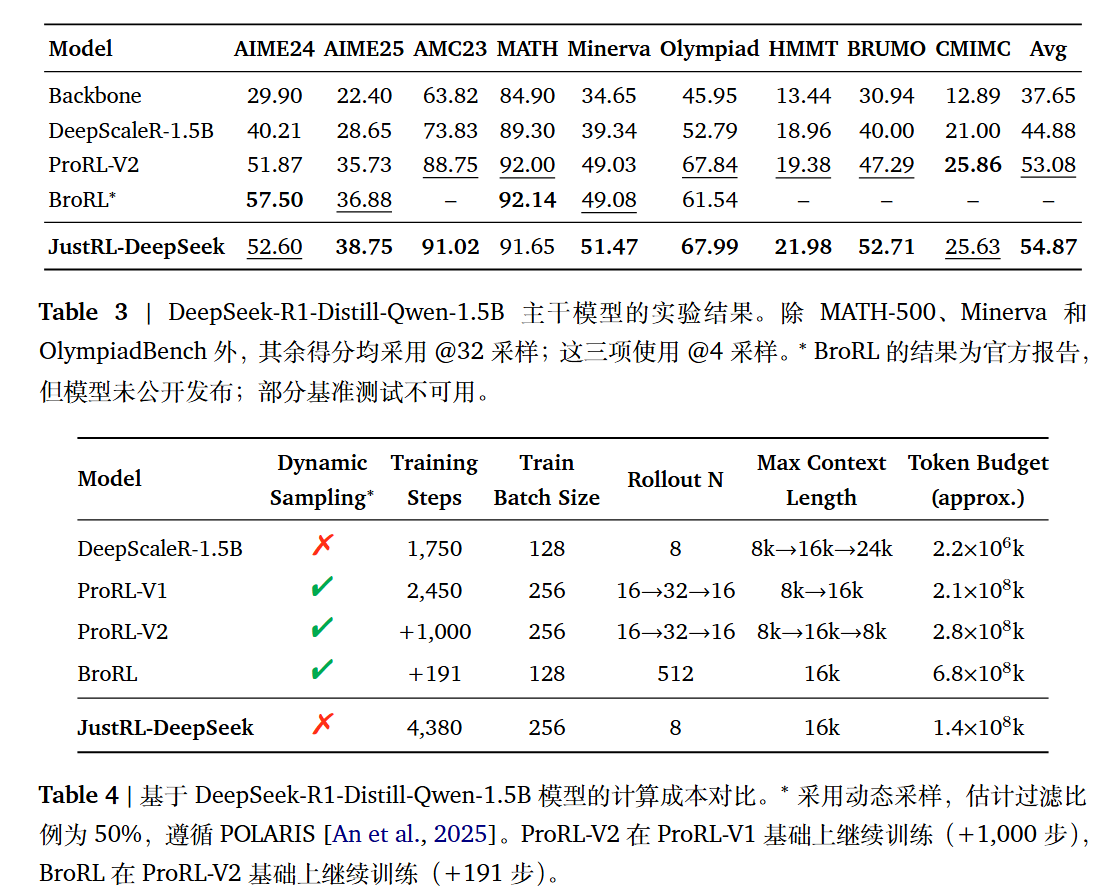
应用于两个主流基座:DeepSeek-R1-Distill-Qwen-1.5B 和 OpenMath-Nemotron-1.5B 。
JustRL-DeepSeek 在 9 个数学基准测试上的平均准确率为 54.87%,超过了采用九阶段训练的 ProRL-V2(53.08%) 。 JustRL-Nemotron 达到了 64.32% 的平均准确率,略高于采用复杂课程学习的 QuestA(63.81%),成为目前该规模下的最优性能 。JustRL 的计算开销比那些复杂的方案低得多。例如,在达到相同或更好性能的前提下,其算力使用量比 ProRL-V2 少 2 倍,比 BroRL 少 4.9 倍 。
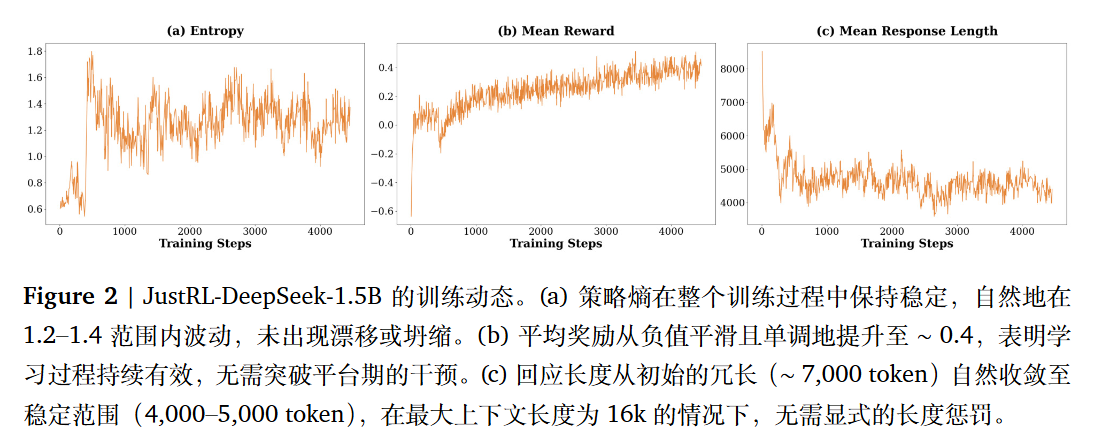
训练动态分析:为什么它有效?
熵(Entropy)稳定: 策略熵自然振荡,没有出现探索崩溃或过早收敛,证明“简单即稳健” 。
奖励平滑提升: 奖励曲线单调上升,没有出现多阶段训练中常见的平台期或突然下跌 。
自然的长度收敛: 模型最初较啰嗦(约 8,000 token),但在没有任何惩罚的情况下,会自然压缩到 4,000-5,000 token 的高效范围。这种“有机压缩”比强制惩罚更具鲁棒性 。
总结
添加“改进”措施反而会降低性能。这暗示,复杂性有时可能解决的是其他设计选择所引发的症状,而非根本的强化学习挑战。
尽管作者展示了简单的强化学习方法效果良好,但无法确定其原因。是超参数?训练数据?验证器设计?还是三者之间的相互作用?作者结果仅限于 1.5B 规模下数学推理中的两种主干模型。推广到其他领域、模型大小和任务仍是一个开放问题。
简单性并非一定有效。在极端计算资源约束下,遇到未曾面对的特定失败模式,或在突破当前性能极限时,又或在奖励信号更嘈杂的领域中,额外的技术可能具有价值。
所以作者认为,首先建立简单的基准,然后仅在识别出复杂性能够解决的具体问题时,再引入更复杂的手段和方法。