Blink:用于增强多模态理解的动态视觉token分辨率
(arxiv 2025)
motivation
目前的多模态模型(如 LLaVA)在处理复杂视觉任务时,往往由于视觉感知能力不足而产生“幻觉” 。
联想回人类,人眼并不会同时以最高精度处理整张图片,而是通过快速扫描发现感兴趣区域,然后聚焦在细节上,并在不同区域间切换注意点 。
现有的增强方法通常需要多次推理,或者只能固定关注单一区域,效率低且灵活性差 。
研究团队通过对 LLaVA-1.5 的内部机制进行实验,得出了两个重要结论:
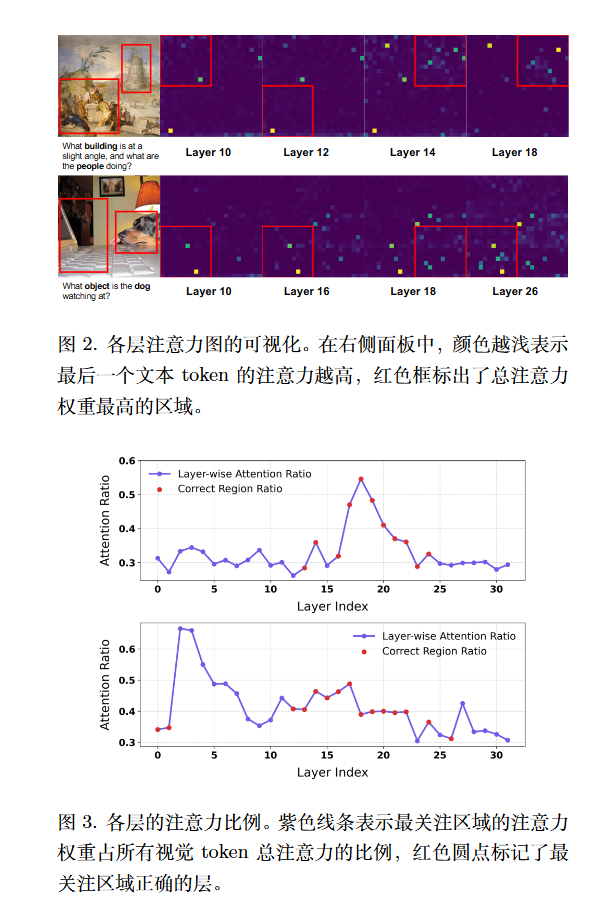
- 结论 1:注意力在层间动态移动。 模型在处理图像时,不同层关注的区域是不同的。正确且锐利的注意力分布通常出现在中间层(约 12-26 层) 。
- 结论 2:增加计算量能提升感知。 如果在某一特定层对高注意力的视觉标记进行复制或增加计算资源,模型对该区域的感知和认知表现会显著增强 。
方法
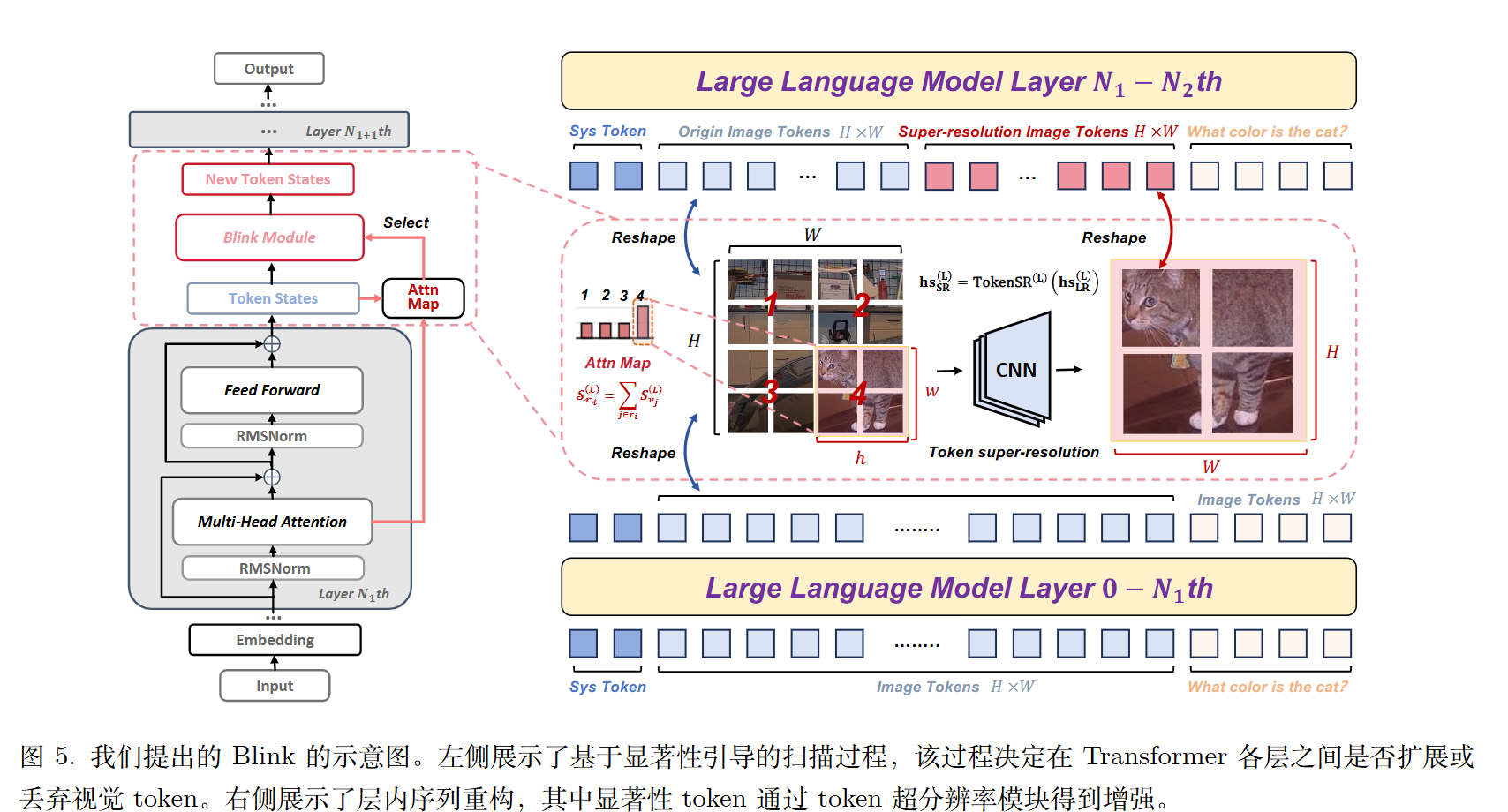
显著性引导扫描 (Saliency-Guided Scanning, SGS)
模型利用文本查询(Query)与图像标记(Key)之间的注意力图来计算每个区域的“显著性分数” 。使用最后一个文本 token 来计算每个视觉 token的显著性。
将图像划分为 $p \times p$ 个区域,计算每个格子的聚合显著性,识别出当前层最重要的区域。
显著性比例 ($\rho$) 用于衡量注意力的聚焦程度。比例越高,表示关注越集中;比例越低,表示关注越分散。
动态标记分辨率 (Dynamic Token Resolution, DTR)
根据显著性比例 $\rho$,模型动态决定“扩张”或“丢弃”:
- 标记扩张 (Token Expansion): 当 $\rho$ 超过设定的阈值 ($\tau_{exp}$) 时,激活一个轻量级的 TokenSR (标记超分辨率) 模块。该模块使用卷积网络将低分辨率标记重构为包含更多细节的高分辨率序列,并插入到原始序列中 。
- 标记丢弃 (Token Drop): 当 $\rho$ 低于阈值 ($\tau_{drop}$) 时,说明当前区域不再重要,模型会移除之前扩张的标记,以恢复效率并防止过度关注无用信息。
Blink:用于增强多模态理解的动态视觉token分辨率
https://lijianxiong.space/2025/20251228-1/