Text-to-LoRA: Instant Transformer Adaption
(ICML 2025)
模块
工作流程:
- 接收一段自然语言的任务描述(Task Description)。
- 使用文本编码器(如
gte-large或 LLM 自身)将描述转换为向量 。 - T2L 超网络根据这个向量,通过一次前向传播(Single Forward Pass),直接输出适配该任务的 LoRA 矩阵(A 和 B)。
- 将生成的 LoRA 权重加载到冻结的基础 LLM 上,模型即刻具备该任务的能力。
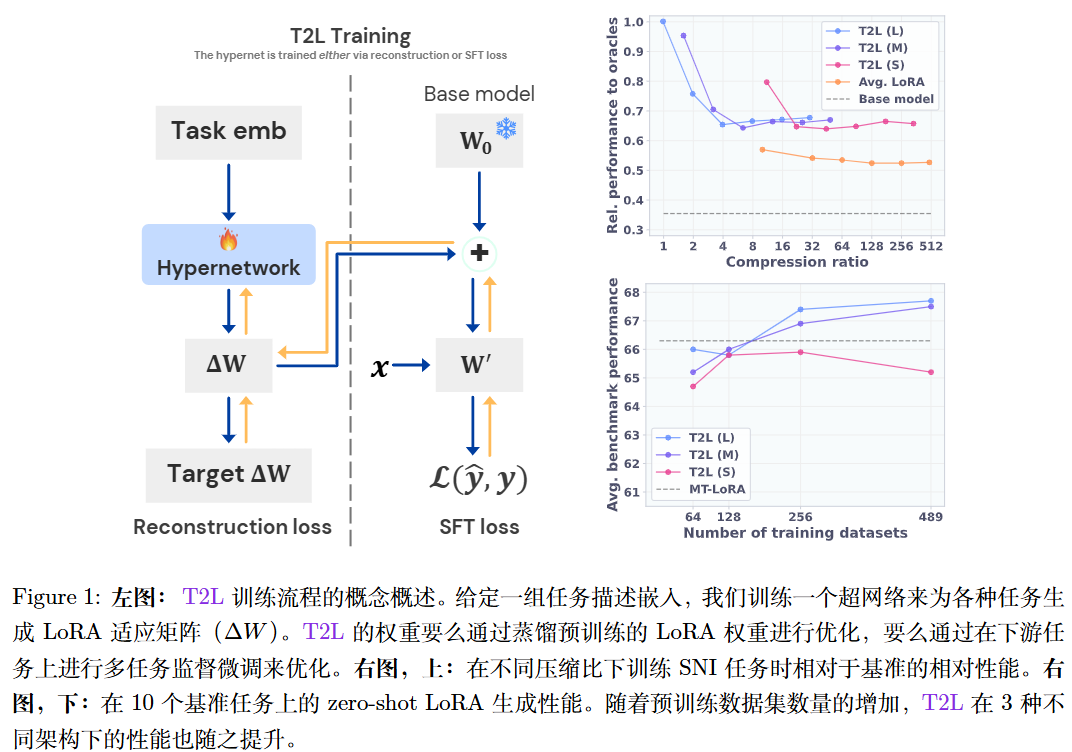
模型架构:
T2L-L (Large): 直接输出完整的 $A$ 和 $B$ 矩阵。参数量最大(~55M)。
T2L-M (Medium): $A$ 和 $B$ 共享输出头,通过 Learned Embedding 来区分生成 $A$ 还是 $B$。参数量中等(~34M)。
T2L-S (Small): 极度压缩,每次只输出矩阵的一行/列(Rank),参数量最小(~5M)。
训练
作者尝试了两种训练策略。
策略一:基于重构的训练 (Reconstruction / Distillation)
先训练好几百个特定任务的 LoRA(作为 Oracle/老师),然后训练 T2L 去“模仿”这些 LoRA 的参数权重 。
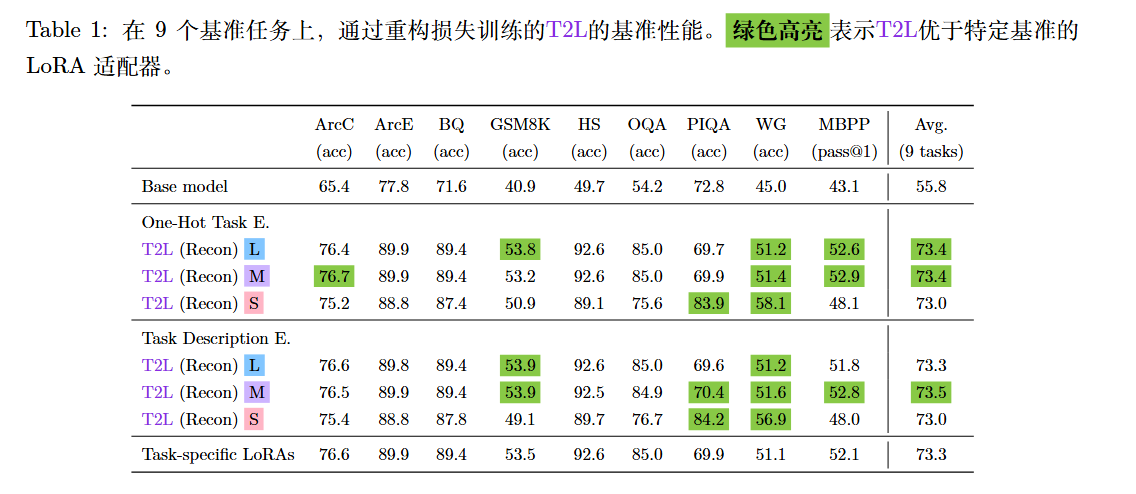
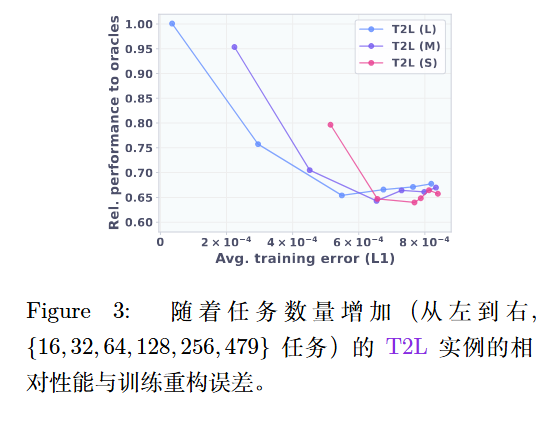
T2L 能够很好地压缩和重建已见过的任务,性能甚至能略微超过原始 LoRA(起到正则化作用)。
但在这种方法的泛化性可能不强。无法泛化到未见过的任务(Zero-shot 失败)。
功能相似的任务(如两个不同的数学任务),其训练出来的 LoRA 权重在参数空间中可能相距甚远(处于不同的局部极小值)。因此,T2L 无法学习到参数空间与任务语义的平滑映射关系 。
策略二:监督微调 (Supervised Fine-Tuning, SFT) —— 推荐方案
不预先训练 LoRA。直接让 T2L 连接到冻结的 LLM 上,使用多任务数据集(Super Natural Instructions, SNI),通过端到端的 Loss(预测 Token 的准确率)来更新 T2L 的参数 。
T2L 能够学习将“任务描述语义”映射到“有效的 LoRA 参数”。
具备强大的零样本(Zero-shot)泛化能力。 即使是训练集中没见过的任务,只要给一段描述,T2L 就能生成有效的适配器 。
实验
单张H100GPU上。
重构 9 个基准特定 LoRA 的训练大约耗时 10 分钟,而重构 479 个 SNI LoRA 适配器的训练则需约 10 小时。
Text-to-LoRA: Instant Transformer Adaption
https://lijianxiong.space/2026/20260110/