mHC:流形约束的超连接
(Deepseek出品)
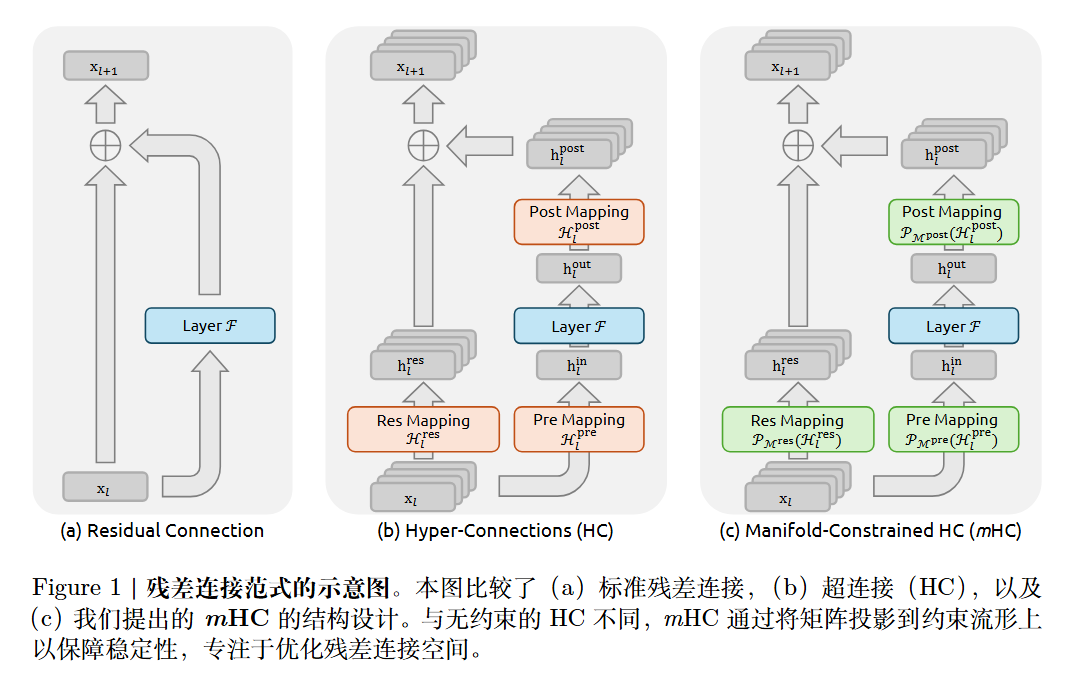
ResNet 引入残差链接方式,解决深层神经网络中的梯度消失/爆炸和网络退化问题。博客也介绍过resnet的一些改进,比如何恺明自己的resnet v2。不过这些改进都算是小打小闹。
残差链接
标准的残差为$h _ {l+1}=h_l+F_l(h_l) $。
如
1 | |
进一步地,可以扩展为$h _ {l+1}=T(h_l)+F_l(h_l) $。
超连接 (Hyper-Connections, HC)
$$
x _ {l+1}=\mathcal{H} _ {l} ^ {res}x _ {l}+\mathcal{H} _ {l} ^ {post~\top}\mathcal{F}(\mathcal{H} _ {l} ^ {pre}x _ {l},\mathcal{W} _ {l})
$$
其中:
$$
\begin{align}
\tilde{x} _ {l} &= \text{RMSNorm}(x _ {l}) \\
\mathcal{H} _ {l} ^ {pre} &= \alpha _ {l} ^ {pre} \cdot \tanh(\theta _ {l} ^ {pre}\tilde{x} _ {l} ^ {\top}) + b _ {l} ^ {pre} \\
\mathcal{H} _ {l} ^ {post} &= \alpha _ {l} ^ {post} \cdot \tanh(\theta _ {l} ^ {post}\tilde{x} _ {l} ^ {\top}) + b _ {l} ^ {post} \\
\mathcal{H} _ {l} ^ {res} &= \alpha _ {l} ^ {res} \cdot \tanh(\theta _ {l} ^ {res}\tilde{x} _ {l} ^ {\top}) + b _ {l} ^ {res}
\end{align}
$$
mhc
mHC 强制要求 Hlres 必须位于 Birkhoff 多胞体(Birkhoff polytope) 内,即满足以下定义的双随机矩阵 :
$$
\mathcal{P} _ {\mathcal{M} ^ {res}}(\mathcal{H} _ {l} ^ {res}) := \{ H \in \mathbb{R} ^ {n \times n} \mid H \mathbf{1}_n = \mathbf{1}_n, \mathbf{1}_n^\top H = \mathbf{1}_n^\top, H \ge 0 \}
$$
这意味着矩阵的所有元素非负,且每一行和每一列的和都严格等于 1。这种约束带来了三个关键的理论优势:
范数保持 (Norm Preservation):双随机矩阵的谱范数(Spectral Norm)不超过 1($||\mathcal{H} _ {l} ^ {res}|| _ {2} \le 1$)。这保证了信号在传播过程中是“非扩张”的,有效防止了梯度爆炸。
组合封闭性 (Compositional Closure):双随机矩阵的乘积仍然是双随机矩阵。这意味着无论网络有多深,复合映射 $\prod \mathcal{H} ^ {res}$ 依然保持稳定,不会发生性质漂移。
几何解释 (Geometric Interpretation):这使得残差映射在几何上表现为特征的凸组合(Convex Combination)。它确保了不同流之间的信息混合是平滑且受控的。
看回公式,类似地:
$$
\begin{equation} \begin{cases} \vec{\mathbf{x}}’_l = \text{RMSNorm}(\vec{\mathbf{x}}_l) \ \ \tilde{\mathcal{H}}_l^\text{pre} = \alpha_l^\mathrm{pre} \cdot (\vec{\mathbf{x}}’_l\phi^\mathrm{pre}_l) + \mathbf{b}_l^\mathrm{pre} \\ \tilde{\mathcal{H}}_l^\text{post} = \alpha_l^\mathrm{post} \cdot (\vec{\mathbf{x}}’_l\phi^\mathrm{post}_l) + \mathbf{b}_l^\mathrm{post} \ \ \tilde{\mathcal{H}}_l^\text{res} = \alpha_l^\mathrm{res} \cdot \text{mat}(\vec{\mathbf{x}}’_l\phi^\mathrm{res}_l) + \mathbf{b}_l^\mathrm{res} \\ \end{cases} \end{equation} \
$$
其中$\text{mat}(\cdot)$为reshape操作为$(\vec{\mathbf{x}}’_l\phi^\mathrm{res}_l)\in\mathbb{R} ^ {1\times n^2}$变换为$\mathbb{R} ^ {n\times n}$。
拉平能更好的保留完整的上下文信息。
另外,我们不使用tanh去约束,因为我们后续还会有Sinkhorn-Knopp去约束。
$$
\begin{align}
\mathcal{H} _ {l} ^ {pre} &= \sigma(\tilde{\mathcal{H}} _ {l} ^ {pre}) \\
\mathcal{H} _ {l} ^ {post} &= 2\sigma(\tilde{\mathcal{H}} _ {l} ^ {post}) \\
\mathcal{H} _ {l} ^ {res} &= \text{Sinkhorn-Knopp}(\tilde{\mathcal{H}} _ {l} ^ {res})
\end{align}
$$
sinkhorn_knopp
经过归一化后的矩阵行列求和均为1
即
$$
\begin{equation} \mathcal{P} _ {\mathcal{M}^\mathrm{res}}(\mathcal{H}^\text{res} _ {l}) \gets \left\{ \mathcal{H}^\text{res} _ {l} \in \mathbb{R} ^ {n \times n} \mid \mathcal{H}^\text{res} _ {l}\mathbf{1}_n = \mathbf{1}_n, \ \mathbf{1}^\top_n\mathcal{H}^\text{res} _ {l} = \mathbf{1}^\top_n, \ \mathcal{H}^\text{res} _ {l} \geq 0 \right\} \end{equation}
$$
SK目标
给定一个矩阵$A \in \mathbb{R} ^ {n \times n}_+$,找到两个对角矩阵$D_1$、$D_2$,使得:
$$
P = D_1 A D_2 \
$$
P的行和为1,列和为1。
迭代过程
设$D_1 = \text{diag}(u)$,$D_2 = \text{diag}(v)$。目标为:$P = \text{diag}(u) , A , \text{diag}(v)$,满足$P \mathbf{1} = \mathbf{1}, \quad P^T \mathbf{1} = \mathbf{1} $
即满足$u \odot (A v) = \mathbf{1}, \quad v \odot (A^T u) = \mathbf{1} $
迭代形式:
$$
u ^ {(t+1)} = \frac{1}{A v ^ {(t)}}, \quad v ^ {(t+1)} = \frac{1}{A^T u ^ {(t+1)}} \
$$
系统优化
虽然 mHC 解决了稳定性问题,但 n 倍宽度的残差流(论文中 n=4)带来了巨大的显存访问(I/O)和通信开销。DeepSeek 团队通过以下底层设计解决了这些问题:
算子融合 (Kernel Fusion)
- Sinkhorn 融合:将 Sinkhorn-Knopp 的 20 次迭代计算融合在一个单一的 Kernel 中,减少 Kernel 启动开销 。
- 混合精度与 I/O 优化:利用 TileLang 开发算子,将 RMSNorm 与矩阵乘法融合,最大化内存带宽利用率,并采用混合精度计算(参数用 float32,计算用 bfloat16) 。
重计算策略 (Recomputing)
- 问题:为了反向传播,通常需要存储所有层的中间激活值,n 倍宽度会导致显存爆炸 。
- 策略:mHC 放弃存储中间层的激活值,仅每隔 Lr 层存储一次输入 xl0。在反向传播时,利用这一层输入重新计算后续层的激活值 。
- 最优块大小:论文推导出了最优的重计算块大小$L_r \approx \sqrt{\frac{nL}{n+2}}$,以在计算开销和显存占用之间取得平衡 。
DualPipe 通信重叠
- 由于残差流变宽,跨 GPU/节点的通信量增加了 n 倍。
- mHC 改进了 DualPipe 调度策略,将 MLP 层的计算放在高优先级流上运行,从而掩盖(Overlap)掉由于扩展残差流带来的通信延迟 。