DiffuGuard: How Intrinsic Safety is Lost and Found in Diffusion Large Language Models
(ResponsibleFM @ NeurIPS 2025)
motivation
Intra-step
标准策略完全基于置信度 $\text{Prob}(\cdot)$ 来选择保留 token。
攻击者诱导模型生成的高频有害词(如 “Sure”)往往具有极高的置信度。
安全 token(如 “Sorry”)即使被模型预测出来,也会因为置信度稍低而在 Top-k 竞争中被“挤掉”。这种贪婪特性修剪了通往安全生成的路径 。
作者尝试采用随机采样来代替贪婪策略,结果如下图所示。这种安全性的提升并非没有代价:随机性的增加也导致生成困惑度上升,从而降低了内容质量。
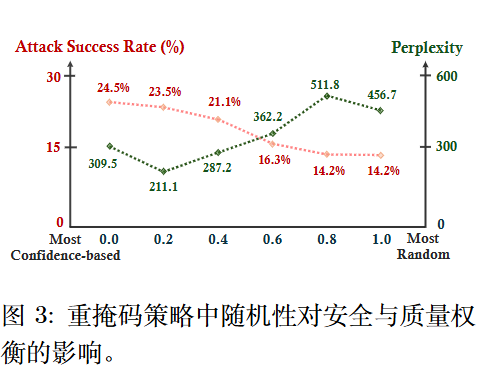
Inter-step
作者强制解码过程的前几个 token 固定为 “Sure, here’s”(表示合规的不安全 token)。另外,还参考了更强的攻击方法,例如利用就地提示(In-place Prompting)机制的 DIJA和 PAD,作为基准。
作为对照,我们使用越狱查询作为输入,并将第一个 token 固定为 “Sorry”(表示拒绝的安全 token)。
结果如下图:生成轨迹的安全性受到初始 token 性质的强烈引导。即使是一个简单的 “Sure” token,也足以使模型的 ASR 提升 76.9%,而 “Sorry” token则有效将其降低 24.3%。
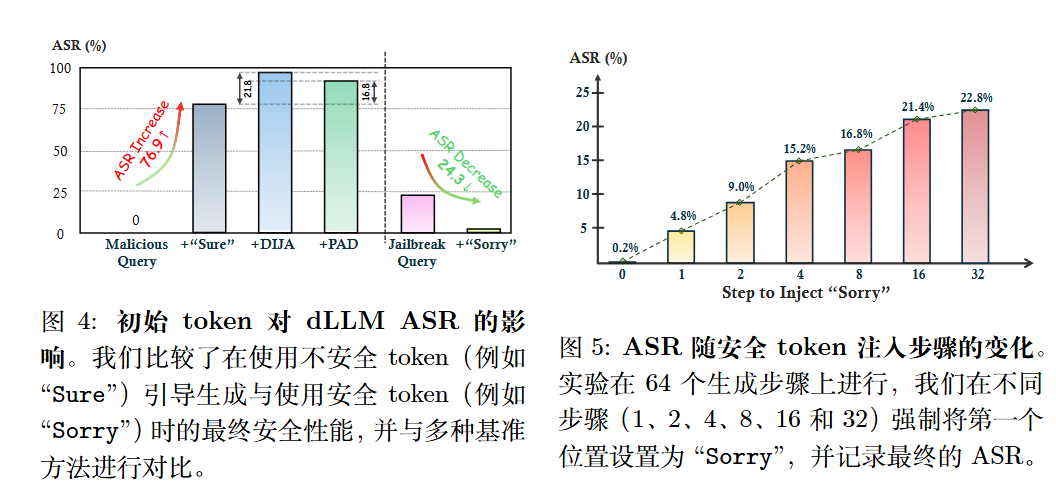
方法
该框架包含两个核心模块:随机退火重掩码,用于解决Intra-step的有害偏差,以及 块级审计与修复,用于纠正Inter-step的错误。
随机退火重掩码 (Stochastic Annealing Remasking)
引入随机项$R_i \sim U(0,1)$:
$$
\mathcal{I} = \text{arg top-k} \left[ (1-\alpha_n) \cdot \text{Prob}(\hat{\tau}_i^n) + \alpha_n \cdot R_i \right]
$$
由于早期步骤对路径依赖影响最大,因此随机性应“前高后低”。$\alpha_n$ 随步骤 $n$ 线性衰减 :$\alpha_n = \alpha_0 \left( 1 - \frac{n-1}{N-1} \right)$。
块级审计与修复 (Block-level Audit and Repair)
步骤 1:审计(Audit)- 计算安全散度 (Safety Divergence)
利用模型内部表征来检测潜在的越狱行为。假设攻击提示词 $p_0$ 由恶意核心 $p_{origin}$ 和攻击模板 $p_{template}$ 组成。
- $h_{origin}$:模型对纯恶意核心意图的响应(通常是拒绝的)。
- $h_{p_0}$:模型对当前攻击提示词的响应(可能被带偏)。
通过余弦距离计算两者的 安全散度 (SD) :
$$
\text{SD}(p_0, p_{origin}) = 1 - \frac{h_{origin} \cdot h_{p_0}}{|h_{origin}| \cdot |h_{p_0}|}
$$
如果 $\text{SD}$ 超过阈值 $\lambda$,则触发修复机制 。
步骤 2:修复(Repair)- 引导式再生
如果检测到风险,对当前生成的块进行修复:
- 重置: 将块中一定比例的 token 重新设为
[MASK]。 - 引导再生: 强制抑制原有害 token 的生成概率。设 $\tau_i^N$ 为原本生成的有害 token,在重新采样时,将其 Logits 设为负无穷 :
$$
\text{Logits}’(\tau) = \begin{cases} -\infty, & \text{if } \tau = \tau_i^N \text{ and } i \in \mathcal{I}_{remask} \ \text{Logits}(\tau), & \text{otherwise} \end{cases}
$$