LLM-VA: Resolving the Jailbreak-Overrefusal Trade-off via Vector Alignment
(arxiv 2026)
Large Language Model Vector Alignment (LLM-VA)
motivation
作者发现,
- 回答决策 ($v_a$):模型决定“回答还是拒绝”的方向。
- 安全判断 ($v_b$):模型判断输入是“良性还是有毒”的方向。
在模型的潜在空间中,这两个向量几乎是正交的(夹角约为 90°)。
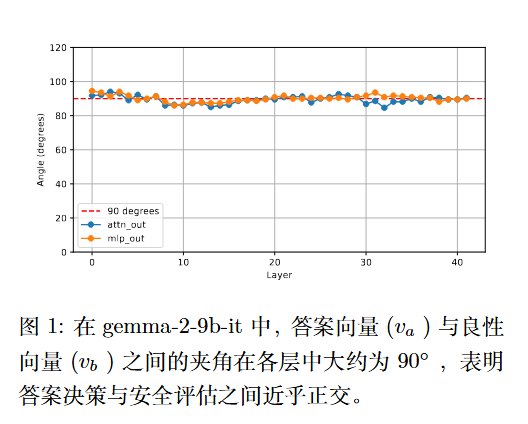
这意味着,模型将“是否回答”和“输入是否安全”视为两个独立的过程 。
方法
既然“是否回答”和“输入是否安全”是两个独立的过程 。我可以通过将“回答向量”($v_a$) 与“良性向量”($v_b$) 进行对齐,强制模型建立因果关系:只有当通过安全评估(良性)时,才触发回答意愿 。
作者使用SVM在每一层寻找两个超平面:
- 区分良性/有毒输入的超平面(法向量为 $v_b$)。
- 区分回答/拒绝行为的超平面(法向量为 $v_a$)。
作者又设计了一个评分机制,选择那些既有影响力(对最终输出贡献大)又准确(SVM 分类准确率高)的层进行修改 :
$$
Score^{(l)} = C_a^{(l)} \cdot Acc_a^{(l)} + C_b^{(l)} \cdot Acc_b^{(l)}
$$
影响力:$C_a^{(l)} = v_a^{(fin)} \cdot v_a^{(l)}$
准确率:$Acc_a^{(l)}$
对于任意输入 $x$,我们希望修改后的权重 $W + \Delta$ 满足以下关系 :
$$x(W+\Delta)v_a = \frac{\sigma_a}{\sigma_b} x W v_b$$
$$
x \Delta v_a = x (\frac{\sigma_a}{\sigma_b} W v_b - W v_a)
$$
$$\Delta v_a = \frac{\sigma_a}{\sigma_b} W v_b - W v_a$$
根据彭罗斯广义逆(Penrose pseudoinverse),使得权重修改量最小(最小范数解)的 $\Delta$ 为 :
$$
\Delta^+ = \left( \frac{\sigma_a}{\sigma_b} W v_b - W v_a \right) v_a^T
$$
最终的权重更新公式为 :
$$W’ = W + \Delta^+$$
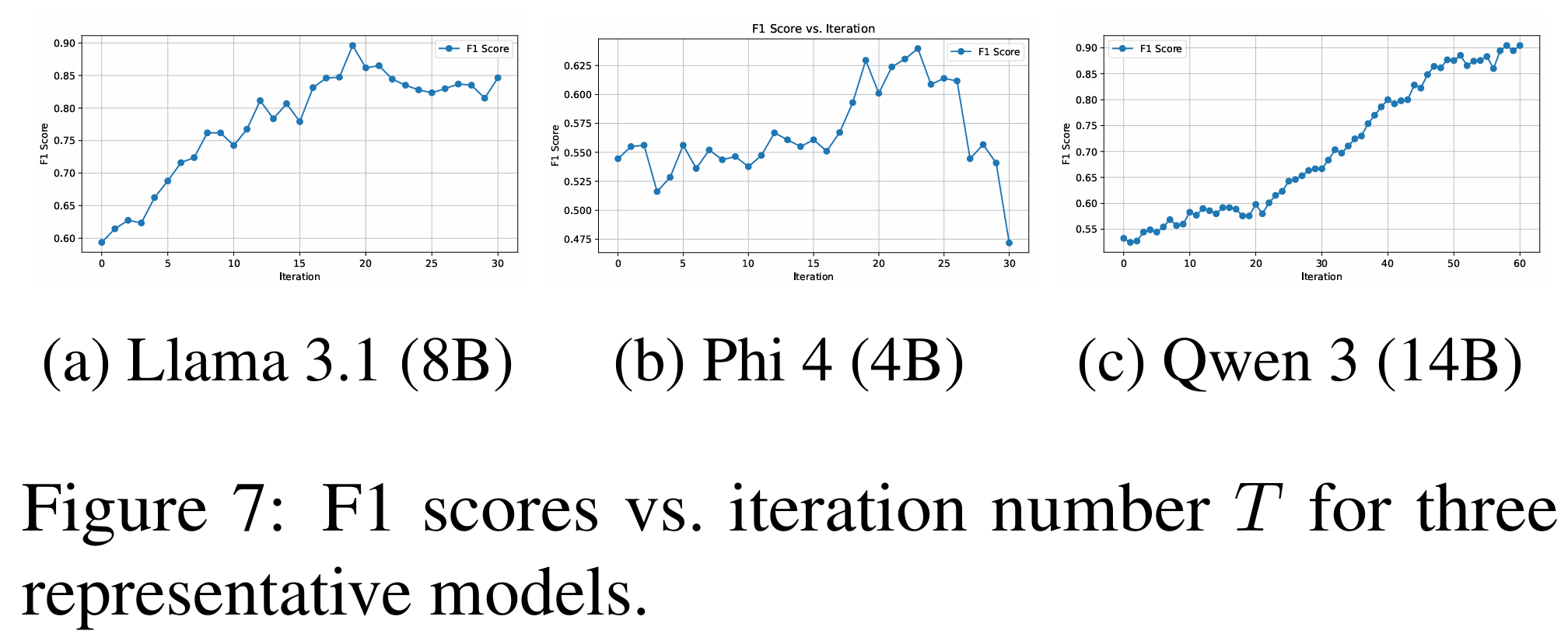
为了避免后续层的 $v_a$ 和 $v_b$ 发生漂移 ,还会进行多次迭代。
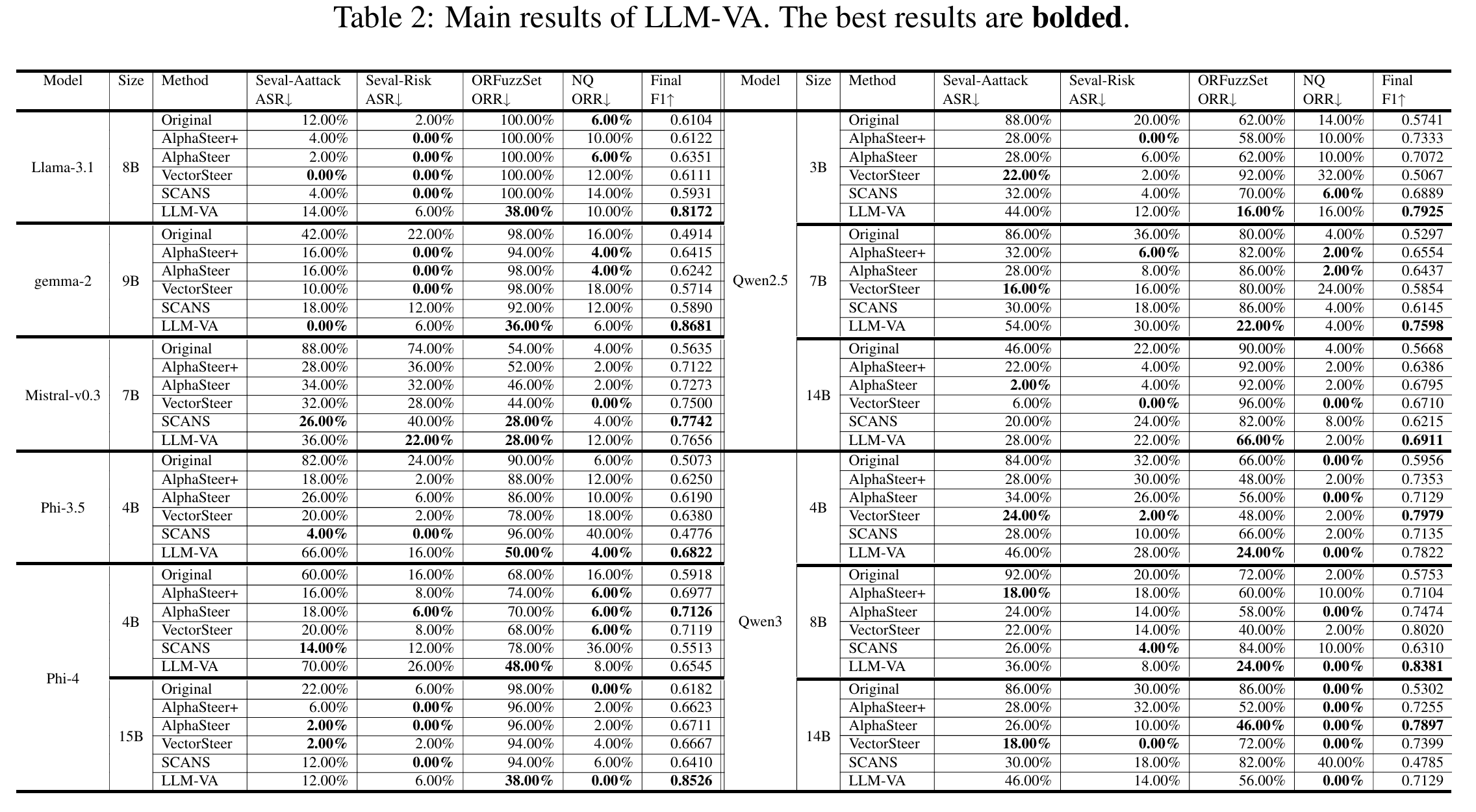
实验显示约 20-30 次迭代收敛。
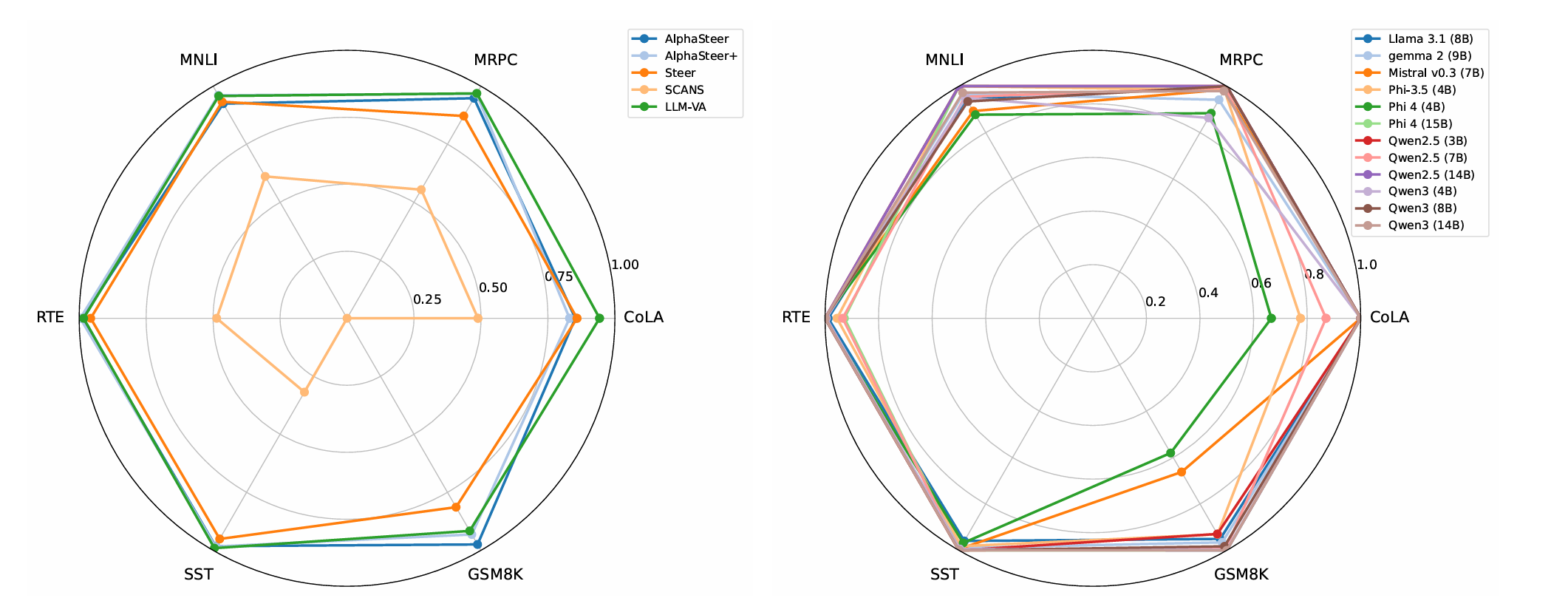
实验
实验部分比较有趣,故记录下来。