Why Steering Works:Toward a Unified View of Language Model Parameter Dynamics
(arxiv 2026)
将全量微调、LoRA、激活干预统一。
很好的文章!
统一
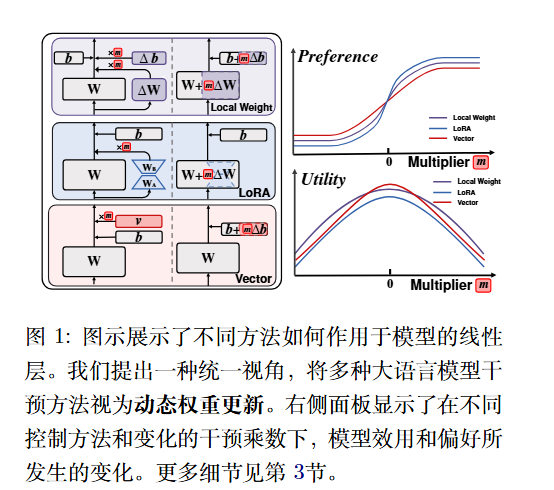
文将所有这些干预方法统一表示为对线性层(Linear Layer)的仿射变换(Affine Transformation)的修改:
$$h_{i+1} = (W + m_1 \Delta W)h_i + (b + m_2 \Delta b)$$
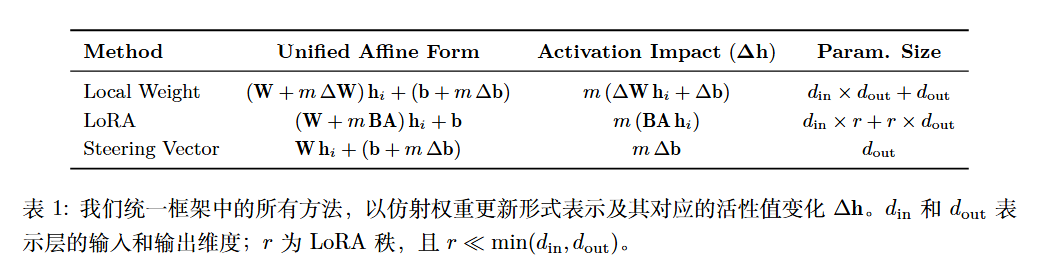
偏好与效用的权衡
论文引入了两个核心指标来衡量控制效果。
假设对于一个查询 $q$,存在一对极性相反的回答:符合目标概念的正向回答 $A_p$ 和负向回答 $A_n$。 论文将生成概率分解为效用概率 $P(u|q)$(代表生成有效文本的能力)和偏好概率 $P(p|q)$(代表倾向于某种概念的程度):
$$
P(A_p|q) = P(u|q)P(p_p|q)
$$
$$P(A_n|q) = P(u|q)P(p_n|q)$$
- 偏好 (Preference):模型生成内容符合目标概念(如“积极情感”)的倾向程度。
$$
PrefOdds(q) = \log \frac{P(p_p|q)}{P(p_n|q)} = \mathcal{L}_n - \mathcal{L}_p
$$
- 效用 (Utility):模型生成内容在任务上的连贯性、有效性和指令遵循能力(即如果不考虑风格,句子本身是否通顺合理)。
$$UtilOdds(q) = \log \frac{P(u|q)}{1 - P(u|q)} = \log \frac{e^{-\mathcal{L}_p} + e^{-\mathcal{L}_n}}{1 - (e^{-\mathcal{L}_p} + e^{-\mathcal{L}_n})}$$
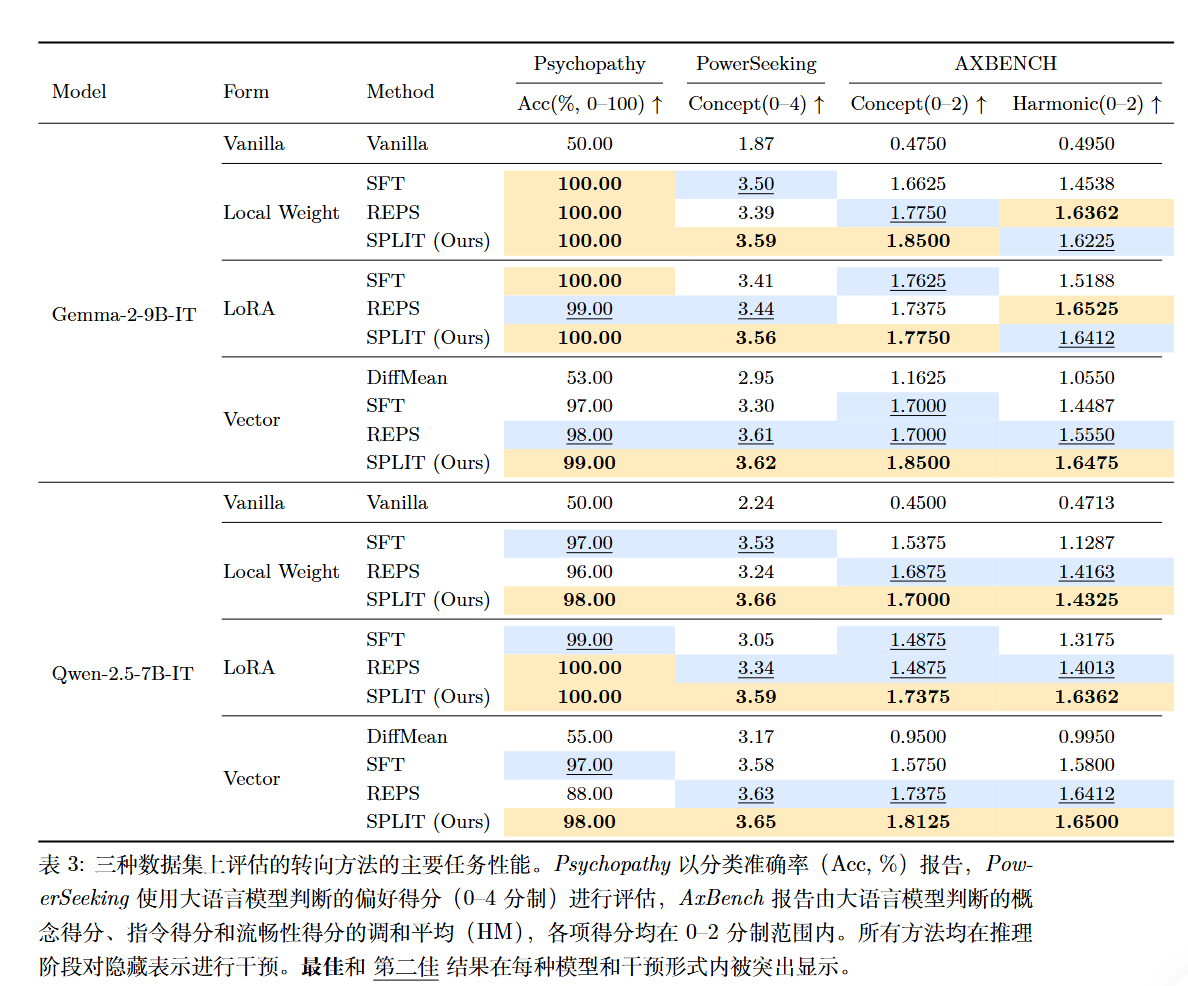
观察到的规律 : 无论使用哪种干预方法(LoRA, Vector, Local Weight),随着控制强度(Multiplier $m$)的变化,模型表现出惊人一致的动力学模式:
- 偏好 (Preference):随着 $m$ 增加,偏好得分呈现 S 形曲线(或线性增长后饱和)。
- 效用 (Utility):随着 $m$ 偏离 0(无论正向还是负向引导),效用得分都会呈现单调下降,形成一个倒“U”形或钟形曲线 。
这揭示了一个普遍的权衡:更强的控制通常以牺牲模型的通用能力(效用)为代价 。
机制分析
论文提出了激活流形假设 (Activation Manifold Hypothesis)。
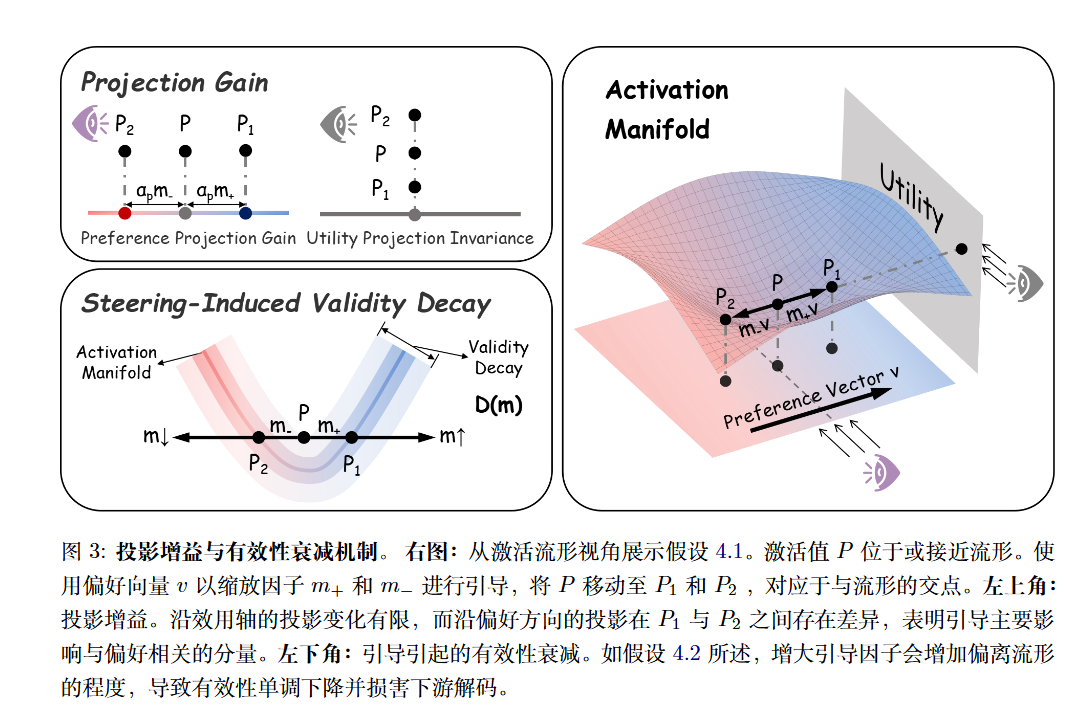
模型的正常激活值位于一个低维流形 $\mathcal{M}_l$ 附近。当干预使激活值 $\tilde{h}(m)$ 远离该流形时,后续层解码的有效性(Validity)会下降 。
论文引入了一个有效性衰减函数 (Validity Decay Function) $D(m)$ 来量化这种偏离,采用分段有理二次形式(Rational Quadratic Form)建模 :
$$D(m) = \left( 1 + \frac{(m - m_{\pm})^2}{2 \alpha l^2} \right)^{-\alpha}$$
论文提出了拟合实验数据的理论模型:
偏好动力学模型: 偏好是由“线性引导”和“非线性衰减”共同作用的结果 :
$$PrefOdds(m) = (\alpha_p m + \beta_p) D_p(m) + b_p$$
- $\alpha_p m$:代表干预向量在偏好方向上的投影增益(线性增长)。
- $D_p(m)$:代表因脱离流形导致的有效性衰减。
- 当 $m$ 较小时,$D(m) \approx 1$,表现为线性增长;当 $m$ 过大,衰减项主导,导致曲线平缓甚至塌陷。
效用动力学模型: 由于干预向量通常与效用方向正交,效用的变化主要由衰减项主导 :
$$UtilOdds(m) = \beta_u D_u(m) + b_u$$
这解释了为什么无论向哪个方向引导(正向或负向),效用通常都会下降。
方法
基于上述分析,论文提出了一种名为 SPLIT (Steering with Preference-Utility Intervention) 的训练目标,旨在在增强偏好的同时,最大程度地保持效用(即延缓 $D(m)$ 的衰减)。
论文提出了两种损失。
效用损失 (Utility Loss) $\mathcal{L}_{util}$: 为了将激活值保持在“流形”上(即保持生成有效文本的能力),模型需要在正向和负向样本上都最小化标准的语言建模损失 :
$$\mathcal{L}_{util} = \lambda_p \mathcal{L}_p + \lambda_n \mathcal{L}_n$$
其中 $\lambda_p, \lambda_n$ 是权重系数。这迫使模型无论输出何种极性的内容,都要保证其符合语言模型的概率分布。
偏好损失 (Preference Loss) $\mathcal{L}_{pref}$: 为了实现控制,模型需要最大化正负样本之间的对数几率差(即偏好对数几率)。论文使用了一个带边缘(margin)的铰链损失形式 :
$$\mathcal{L}_{pref} = \gamma \cdot \sigma(\theta - (\mathcal{L}_n - \mathcal{L}_p))$$
其中 $\sigma(\cdot)$ 是 ReLU 函数,$\theta$ 是目标边缘,$\gamma$ 是权重。这鼓励 $\mathcal{L}_n$ 显著大于 $\mathcal{L}_p$,从而提高 $PrefOdds$。
最终损失函数为 :
$$\mathcal{L} = \mathcal{L} _ {util} + \mathcal{L} _ {pref}$$
通过联合优化这两个目标,SPLIT 方法能够在提升模型对目标概念(如特定情感、风格)的依从性的同时,防止模型因过度干预而输出崩坏,实现了更好的偏好-效用权衡 。
实验