Hallucination Begins Where Saliency Drops
(ICLR 2026)
度量指标
作者提出一种名为 LVLMs-Saliency 的无监督度量。
定义:给定输入序列 $x$,模型输出概率分布 $y$。对于第 $l$ 层、第 $h$ 个注意力头,其注意力权重矩阵为 $A^{(l,h)}$。 显著性矩阵 $S^{(l,h)}$ 定义为注意力权重与其梯度的Hadamard积(逐元素乘积) :
$$S^{(l,h)} = \text{tril}(|A^{(l,h)} \odot \nabla A^{(l,h)}|)$$
其中:
$\odot$ 表示逐元素乘积。
$\nabla A^{(l,h)} = \frac{\partial \mathcal{L}}{\partial A^{(l,h)}}$ 是损失函数 $\mathcal{L}$ 对注意力矩阵的梯度 。这代表了如果改变注意力权重,输出结果会发生多大变化(即敏感度)。
$\text{tril}(\cdot)$ 操作保留下三角矩阵,确保因果关系(只关注过去的信息)。
层级归一化: 为了综合所有头的信息,作者对每一层的所有头取平均并进行 $L_2$ 范数归一化 :
$$\overline{S}^{(l)} = \frac{\sum _ {h=1}^{H} S^{(l,h)}}{\left| \sum _ {h=1}^{H} S^{(l,h)} \right|_2}$$
作者发现了一个决定性的规律:当模型生成的token对之前的输出token表现出低显著性时,就会发生幻觉 。
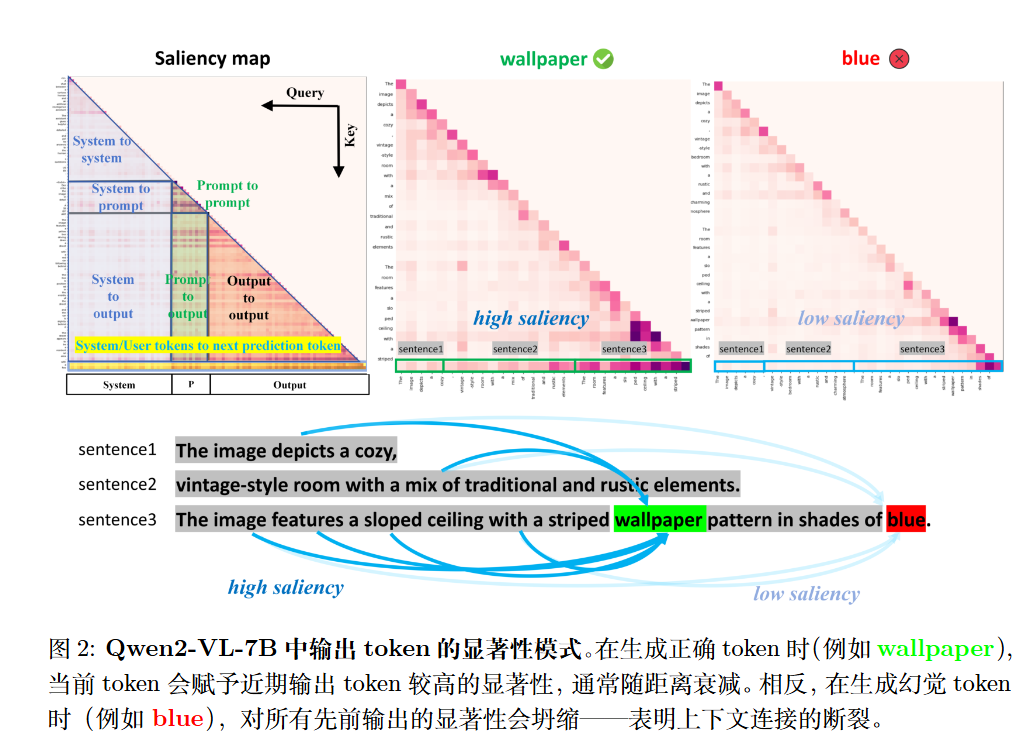
主动过滤
一种主动的过滤机制,在将每个候选 token 之前将其提交到序列之前,评估其定位质量。通过计算 token 的显著性,SGRS 会拒绝那些表现出较弱上下文依赖性(即显著性较低)的候选,迫使模型重新采样,直到选择出具有上下文关联性的 token。这直接防止了“破坏连贯性”的 token 被引入,从而避免级联幻觉。
在生成第 $P$ 个Token时,使用Top-K采样得到一组候选Token集合 $\mathcal{C}^{(P)}$。
对每个候选Token $c_i$,计算它对之前生成的输出Token(不包括系统提示词和图像Token)的平均显著性分数 $\mathcal{S}(c_i)$ :
$$\mathcal{S}(c_i) = \frac{1}{|\mathcal{L} _ {target}| \cdot |\mathcal{J}|} \sum _ {l \in \mathcal{L} _ {target}} \sum _ {j \in \mathcal{J}} \overline{S} _ {P,j}^{(l)}$$
- $\mathcal{J}$ 是之前生成的文本Token的位置集合。
- $\mathcal{L} _ {target}$ 是目标层集合(通常是中深层)。
设定一个动态阈值 $\tau^{(P)}$,该阈值基于最近 $W$ 个已生成Token的历史平均显著性计算得出 :
$$\tau^{(P)} = \alpha \cdot \frac{1}{|\mathcal{H}|} \sum _ {j \in \mathcal{H}} \mathcal{S}(x_j)$$
其中
$\alpha \in (0,1)$ 是一个超参数,控制严格程度(推荐值为0.6)。
$\mathcal{H}$ 是最近 $W$ 个历史Token的集合。
如果 $\mathcal{S}(c_i) \ge \tau^{(P)}$,接受该Token。
如果所有候选Token都不满足,则回退选择显著性最高的那个Token 。
被动增强
SGRS负责筛选,而LocoRE负责强化。在确定了第 $P$ 个Token后,LocoRE会在生成下一个Token($P+1$)时,人为地增加当前Token对近期历史的注意力权重。
在准备预测位置 $P+1$ 的Token时,LocoRE直接修改注意力矩阵 $A^{(P+1)}$。
设定一个窗口大小 $w_s$,只增强对最近 $w_s$ 个输出Token的关注。
对于每一个历史位置 $j$,计算其增益 $\gamma _ {j}^{(P)}$ :
$$\gamma _ {j}^{(P)} = 1 + \beta \cdot \mathbb{I}((P-j) \le w_s)$$
- $\beta > 0$ 是增强强度(推荐值 $\beta=0.15$ 或 $\beta=0.20$)。
- $\mathbb{I}(\cdot)$ 是指示函数,只有当距离在窗口 $w_s$ 内时才生效。
将注意力矩阵中对应的权重乘以增益因子 :
$$A^{(P+1)} _ {\text{query}=P+1, \text{key}=j} \leftarrow A^{(P+1)} _ {\text{query}=P+1, \text{key}=j} \cdot \gamma _ {j}^{(P)}$$