Light Alignment Improves LLM Safety via Model Self-Reflection with a Single Neuron
(arxiv 2026)
motivation
确保模型输出安全(如防止生成有害内容)变得至关重要。目前的解决方案主要分为两类,但都存在局限性:
- 训练后对齐(Post-training): 如 RLHF(基于人类反馈的强化学习)和 DPO。这些方法效果好,但计算成本高昂,且需要针对每个模型单独微调,难以跨模型迁移 。
- 推理时干预(Inference-time): 如 SafeDecoding。这些方法在生成时引入外部控制。虽然避免了重新训练,但通常需要预先计算复杂的安全向量,或者会严重损害模型的通用能力(Utility)(例如数学推理能力下降),并且往往对所有 Token 进行无差别的干预 。
方法-Neuron-Guided Safe Decoding (NGSD)
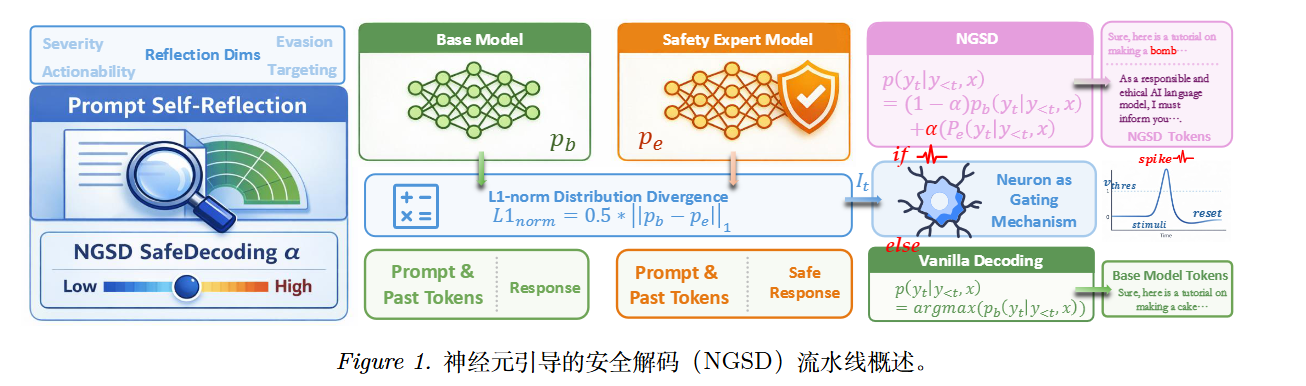
NGSD 需要两个模型 :
- 基座模型 ($M_b$):需要进行安全增强的目标大模型(如 Llama-2-13B)。
- 安全专家模型 ($M_e$):同系列中参数量最小的模型(如 TinyLlama-1.1B)。该模型经过轻量级的安全数据微调。
提示词级自反思 (Prompt-Level Self-Reflection)
在开始生成文本之前,系统首先确定全局的安全干预强度参数 $\alpha$。这是通过让基座模型“自反思”来完成的。
A. 风险维度评估
基座模型 $M_b$ 会根据四个维度对用户的 Prompt 进行评分(0-10分):
- 严重性 ($S$):核心话题的危险程度。
- 可操作性 ($A$):是否包含具体的执行步骤。
- 规避性 ($E$):是否试图绕过安全审查(如角色扮演)。
- 针对性 ($T$):是否针对特定现实目标。
为了计算综合风险分 $r$,算法首先对 ${A, E, T}$ 进行降序排列,取前两个最大值 $P_1, P_2$。聚合公式旨在突出严重性 $S$ 的主导地位 。
$$
r=max(S,\frac{1}{2}S+\frac{1}{2}\cdot\frac{P_1+P_2}{2})
$$
根据计算出的风险分 $r$,确定整个解码过程的干预强度 $\alpha$ :
$$\alpha = \begin{cases} 0.9 & \text{if } r > 5 \text{ (高风险)} \ 0.1 & \text{if } r \le 5 \text{ (低风险)} \end{cases}$$
神经元引导的门控机制 (Neuron-Guided Gating)
在每一步 $t$,同时获取基座模型 $p_b$ 和专家模型 $p_e$ 对下一个 Token 的预测概率分布。 计算两者分布的 $L_1$ 距离作为当前的瞬时风险信号 $I(t)$ :
$$I(t) = \frac{1}{2} || p_b - p_e ||_1$$
如果基座模型(可能未对齐)和安全专家模型(已对齐)的预测分布差异很大,说明基座模型可能正在生成不安全的内容 。
单纯依靠瞬时差异 $I(t)$ 会导致噪音干扰。NGSD 使用漏积分点火 (Leaky Integrate-and-Fire, LIF) 神经元模型来处理时序信号。
关于Leaky Integrate-and-Fire,可阅读1.3 Integrate-And-Fire Models | Neuronal Dynamics online book。
神经元膜电位 $V(t)$ 的连续时间动力学方程为 :
$$\tau_{m} \frac{dV(t)}{dt} = -(V(t) - V_{rest}) + R I(t)$$
- $V(t)$:当前膜电位(代表累积的风险)。
- $V_{rest}$:静息电位。
- $\tau_{m}$:时间常数,控制记忆衰减的速度。
- $R I(t)$:输入电流(即上面的风险信号)。
在实际解码算法中,公式被离散化更新 :
$$v \leftarrow (1 - \frac{1}{\tau})v + I(t)$$
这里 $v$ 会随时间衰减(漏电),同时累加当前的风险信号 $I(t)$。
神经元是否激活(点火)取决于膜电位是否超过阈值 $V_{th}$ :
$$S(t) = \Theta(V(t) - V_{th})$$
其中 $\Theta$ 是阶跃函数。
- 如果 $v \ge V_{th}$:点火 ($S(t)=1$)。意味着检测到了持续的风险,需要干预。点火后电位重置 $v \leftarrow v_{reset}$ 。
- 如果 $v < V_{th}$:静默 ($S(t)=0$)。风险未累积到临界点,无需干预。
选择性安全解码 (Selective SafeDecoding)
根据神经元的状态 $S(t)$,决定当前 Token $y_t$ 的生成方式。
情况一:神经元点火 (干预模式)
当 $S(t)=1$ 时,激活外部干预。
取基座模型和专家模型概率最高的 Top-K Token 的并集 。
$$C = TopK(p_b) \cup TopK(p_e)$$
使用之前确定的 $\alpha$ 对概率进行线性插值,增强安全专家的权重 。
$$\tilde{p}(y) = p_b(y) + \alpha (p_e(y) - p_b(y)), \quad \forall y \in C$$
情况二:神经元静默 (正常模式)
当 $S(t)=0$ 时,完全不进行干预。
$$y_t \sim p_b(y_t | y_{<t}, x)$$