Learning to Reason in 13 Parameters
(arxiv 2026)
LoRA是W‘=W+AB,其中$A \in \mathbb{R}^{d \times r}$,$B \in \mathbb{R}^{r \times k}$,故参数量为$\mathcal{O}(dr)$。
而LoRA-XS变为$W’ = W + U \Sigma R V^\top$,参数量为$\mathcal{O}(r^2)$。这可
以看作是学习重新组合 W 的主导奇异方向。
而本文的tiny-LoRA进一步变为$W’ = W + U\Sigma (\sum_{i=1}^{u} v_i P_i) V^\top$。
其中:
$v \in \mathbb{R}^{u}$:一个极小的可训练向量,维度为 $u$($u$ 可以小到 1)。
$P \in \mathbb{R}^{u \times r \times r}$:一组固定(frozen)且随机初始化的矩阵张量。
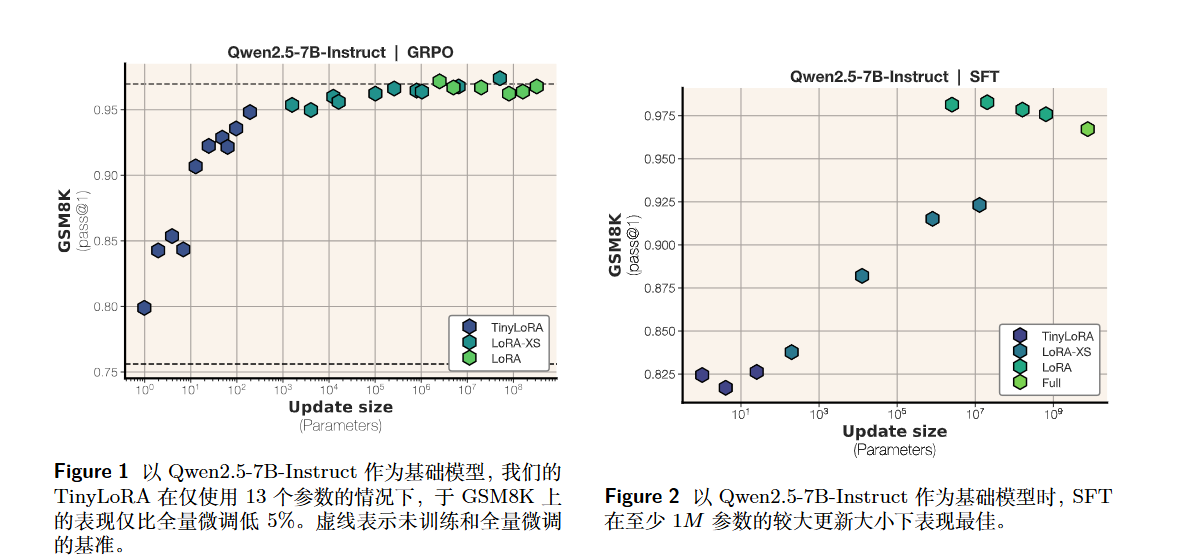
这种极低参数量的方法在**监督微调(SFT)中表现不佳,但在强化学习(RL)**中非常有效 。
- 信息密度假设: 作者认为 SFT 需要模型吸收大量关于“具体回答是什么”的信息(包含噪声),因此需要较大的容量。
- RL 的稀疏性: RL(特别是带有验证奖励的 RL)只需要学习一个使得奖励最大化的“方向”或“风格”(例如生成更长的思维链),这种信号更稀疏且清晰,因此可以通过极少的参数(即调整 hidden states 的主要奇异值方向)来实现 。
Learning to Reason in 13 Parameters
https://lijianxiong.space/2026/20260215/