EMNLP 2025关于幻觉的论文
共20篇。
(1)MedHallu: A Comprehensive Benchmark for Detecting Medical Hallucinations in Large Language Models
pass
(2)Active Layer-Contrastive Decoding Reduces Hallucination in Large Language Model Generation
在标准的层对比解码(如 DoLa)中,模型通过对比浅层(包含更多句法和表面模式)和深层(包含更多事实和语义知识)的输出来预测下一个词 。 设 $q_N$ 为浅层的对数概率(logits),$q_M$ 为深层的对数概率 。传统的层对比解码公式如下 :
$$p(x_t|x _ {<t}) = \text{softmax}(\mathcal{F}(q_N(x_t), q_M(x_t)))$$
其中,$\mathcal{F}(\cdot, \cdot)$ 是一个对比操作符,用于放大深层中高置信度的预测,同时抑制浅层中可能具有误导性的模式 。
ActLCD引入了一个二元动作变量 $a_t \in {0, 1}$,用于决定当前步是否激活层对比 。改进后的解码概率分布公式为 :
$$p(x_t|x _ {<t}) = \text{softmax}(a_t \cdot \mathcal{F}(q_N(x_t), q_M(x_t)) + (1 - a_t) \cdot q_M(x_t))$$
- 当 $a_t = 1$ 时,模型执行层对比解码(重点关注事实性)。
- 当 $a_t = 0$ 时,模型退回到标准的贪婪解码 $q_M(x_t)$(正常生成,不额外消耗对比计算)。
为了学习到最优的动作变量 $a_t$,研究者将解码过程转化为一个马尔可夫决策过程(MDP),表示为 $\mathcal{M} = (\mathcal{S}, \mathcal{A}, P_a, R)$ :
状态 (State) $s_t$:由当前已生成上下文 $x _ {<t}$ 导出的模型内部特征(如中间层的 embeddings 和 logits)构成 。
动作 (Action) $a_t$:动作空间为 ${0, 1}$,即是否激活层对比 。
奖励 (Reward) $R(s_t, a_t)$:这是一个序列级别的奖励,通过与真实的 token 级别标注(该 token 是否真的需要被纠正)进行对比来计算 。
- 真阳性 (True Positive):正确地激活了层对比,奖励 $r _ {tp} = 1.0$ 。
- 真阴性 (True Negative):正确地保持了不激活,奖励 $r _ {tn} = 2.0$(鼓励模型在不需要时保持高效)。
- 假阳性 (False Positive):不必要的激活,惩罚 $r _ {fp} = -1.0$ 。
- 假阴性 (False Negative):漏掉了必要的激活(可能导致严重幻觉),受到重罚 $r _ {fn} = -5.0$ 。
为了训练这个策略网络 $\pi_\theta(a_t|s_t)$,作者采用了离线强化学习框架 BCQ(Batch-Constrained deep Q-learning),分为两个阶段 :
第一阶段:行为克隆 (Behavior Cloning, BC) 首先训练一个神经网络 $\pi_\phi$ 来模仿离线标注数据中的真实激活行为 。通过最小化交叉熵损失来优化:
$$\mathcal{L} _ {BC} = -\sum_t \log \pi_\phi(a_t|s_t)$$
这一步为后续的 Q 学习提供了一个极佳的初始化,并用于限制策略不要偏离真实数据分布太远 。
第二阶段:Q 学习 (Q-learning) 训练一个 Critic 网络 $Q_\theta$ 来预测状态-动作对的累积奖励期望 。为了防止模型在未见过的状态下盲目自信(外推误差),BCQ 施加了一个概率阈值 $\tau$ 。模型只能在行为克隆策略认为概率大于 $\tau$ 的“允许动作集合”中进行选择 :
$$\mathcal{A} _ \phi(s _ {t+1}) = \{a | \pi _ \phi(a|s _ {t+1}) > \tau\}$$
Critic 网络的参数 $\theta$ 通过最小化时序差分(TD)误差进行更新 。
在实际生成文本时,策略网络会在每生成一个词前,评估当前状态 $s_t$ 。它首先找出符合阈值条件的允许动作集合 $\mathcal{A}_\phi(s_t)$,然后选择其中 Q 值(预期回报)最高的动作 :
$$\pi _ \theta = \arg\max _ {a \in \mathcal{A} _ \phi(s_t)} Q _ \theta(s_t, a)$$
由此动态决定是否调用层对比机制。
(3)Shallow Focus, Deep Fixes: Enhancing Shallow Layers Vision Attention Sinks to Alleviate Hallucination in LVLMs
作者提出了一种名为 EVAS (Enhancing Vision Attention Sinks) 的免训练、即插即用的方法 。
在模型的浅层(特别是第1和第2层),图像 token 的注意力汇聚呈现“密集(dense)”状态;而在深层,则变得“稀疏(sparse)” 。
当模型生成非幻觉 token 时,往往会激活大量密集的视觉汇聚头;相反,当模型生成幻觉 token 时,激活的密集视觉汇聚头数量很少,大部分都是稀疏的 。
当视觉注意力汇聚过于稀疏时,模型对视觉 token 的关注度会过度集中在某些特定元素上,导致丧失对图像其他部分的全局视野 。相反,密集的视觉汇聚有助于模型保持全局视角,防止信息丢失,从而降低产生幻觉的概率 。
前置定义
掩码矩阵 (Mask Matrix):为了在计算注意力时忽略对角线元素(自身对自身的注意力),定义了一个掩码矩阵 $M$ :
$$M \leftarrow eye(r,c) - diag(1)$$
这里 $eye(r,c)$ 是单位矩阵,把对角线元素设为 0 。
视觉汇聚 (Vision Sink):假设 $h _ {i,j}$ 是第 $i$ 层、第 $j$ 个注意力头(Head)的注意力图(Attention map) 。对于其中的某一列 $y$,如果它在图像 token 的范围内(例如索引 $k \in [36, 611]$),且其平均注意力得分大于某个阈值 $\beta$,则定义该列为一个“视觉汇聚” 。判断公式为:
$$\frac{\sum _ {x=k} ^ {r} h _ {i,j}[x][y] \cdot M}{r-k} > \beta$$
密集视觉汇聚头 (Dense Vision Sink Head):对于某个特定的注意力头 $(i, j)$,计算它内部满足上述“视觉汇聚”条件的列所占的比例,记为 $\alpha ^ {i,j}$ 。计算公式为:
$$\alpha ^ {i,j} = \frac{Num(vision_sink)}{576}$$
如果这个比例超过了预设的阈值 $\gamma$,即 $\alpha ^ {i,j} \ge \gamma$,那么这个注意力头 $(i, j)$ 就被归类为“密集视觉汇聚头” 。
方法
在特定的浅层(比如第 1 层或第 2 层)中,遍历所有的注意力头(通常是 32 个) 。计算每个头包含的“视觉汇聚”数量 $C _ {i,j}$ 。
找出包含视觉汇聚数量最多的那个头的索引,记为 $n$ :
$$n = \arg\max _ {(C _ {i,j},j) \in H} C _ {i,j}$$
提取这个具有最密集视觉汇聚的注意力头 $n$ 的注意力矩阵,并将其复制并覆盖给同一层的所有其他注意力头 :
$$A[i][j] = A[i][n]$$
(4)Calibrating Verbal Uncertainty as a Linear Feature to Reduce Hallucinations
论文区分并对齐了模型内部的两种“不确定性”:
语义不确定性 (Semantic Uncertainty, SU):指模型对其所生成内容含义的内在不确定性 。论文中通过计算一组语义等价答案上的概率分布熵(即语义熵)来衡量这种内心的不确定度 。
口头不确定性 (Verbal Uncertainty, VU):指模型在输出文本中用语言表达出来的怀疑程度(例如:“我不确定,但是……”) 。论文采用“LLM作为裁判 (LLM-as-a-Judge)”的方法,通过辅助模型来为生成的答案打分,以量化这种不确定性 。
作者使用语义熵来定义语义不确定性。
研究发现,这种表现出来的语气不确定性是由一个单一的线性方向控制的 。
为了提取这个方向,作者使用了均值差技术 (Difference-in-means) 。
首先,收集两组问答数据。一组是模型回答时带有高口头不确定性的问题集合,记为 $\mathcal{D} _ {uncertain}$;另一组是回答时带有低口头不确定性(即语气很肯定)的问题集合,记为 $\mathcal{D} _ {certain}$ 。
对于模型的第 $l$ 层,提取模型在处理这两组问题时,最后一个 token 的残差流激活值(隐藏状态) $h ^ {(l)}(x)$,并分别求均值,然后计算两者的差值 :
$$\hat{r} _ {VU} ^ {(l)} = \frac{1}{|\mathcal{D} _ {uncertain}|} \sum _ {x \in \mathcal{D} _ {uncertain}} h ^ {(l)}(x) - \frac{1}{|\mathcal{D} _ {certain}|} \sum _ {x \in \mathcal{D} _ {certain}} h ^ {(l)}(x)$$
为了得到一个纯粹的方向向量,需要将计算出的差值向量进行 L2 标准化,得到最终的口头不确定性特征 (VUF) $r _ {VU} ^ {(l)}$ :
$$r _ {VU} ^ {(l)} = \frac{\hat{r} _ {VU} ^ {(l)}}{||\hat{r} _ {VU} ^ {(l)}||}$$
传统的幻觉检测往往只关注“语义不确定性 (Semantic Uncertainty, SU)”,即模型内心到底懂不懂 。但这篇论文提出,高语义不确定性(内心没底)加上低口头不确定性(嘴上很硬)的组合,才是导致严重幻觉的元凶 。
为了高效计算,作者没有每次都通过大量采样来评估不确定性,而是训练了线性模型(Uncertainty Probes) 。这些探测器读取模型问题最后一个 token 的隐藏状态,直接预测出数值化的“口头不确定性 (VU)”和“语义不确定性 (SU)” 。
在测试时,将这两个预测出的不确定性数值输入到一个简单的逻辑回归模型中,以此来判断当前生成的答案是否存在幻觉 。实验证明,加入 VU 后,检测的准确率 (AUROC) 得到了显著提升 。
既然找到了控制口头不确定性的方向向量 (VUF),并且能够检测到幻觉风险,我们就可以在模型推理(生成回答)的过程中直接进行干预,强行把模型的语气“扳”向不确定 。
干预不能是盲目的。我们需要计算需要“补充”多少不确定性。干预强度 $\alpha _ {su}(x)$ 被定义为经过归一化的语义不确定性 $su(x) _ {norm}$ 与现有的口头不确定性 $vu(x)$ 之间的差值 :
$$\alpha _ {su}(x) = clip(su(x) _ {norm} - vu(x), 0, max _ {\alpha})$$
在确定了干预强度后,对于检测出可能产生幻觉的响应,在模型的第 $l$ 层,将其隐藏状态 $h ^ {(l)}(x)$ 沿着 VUF 的方向移动相应的步长 :
$$h ^ {(l)}(x) \leftarrow h ^ {(l)}(x) + \alpha _ {su}(x) * r _ {VU} ^ {(l)}$$
(5)Bridging External and Parametric Knowledge: Mitigating Hallucination of LLMs with Shared-Private Semantic Synergy in Dual-Stream Knowledge
传统的 RAG 方法面临两大挑战:
- 上下文间冲突(Inter-context conflict):LLM 往往过度依赖外部证据,而检索到的外部知识可能包含噪声,从而导致模型整体性能下降。
- 上下文-记忆冲突(Context-memory conflict):外部引入的知识可能与 LLM 在预训练阶段学到的参数化(内部)知识产生冲突。
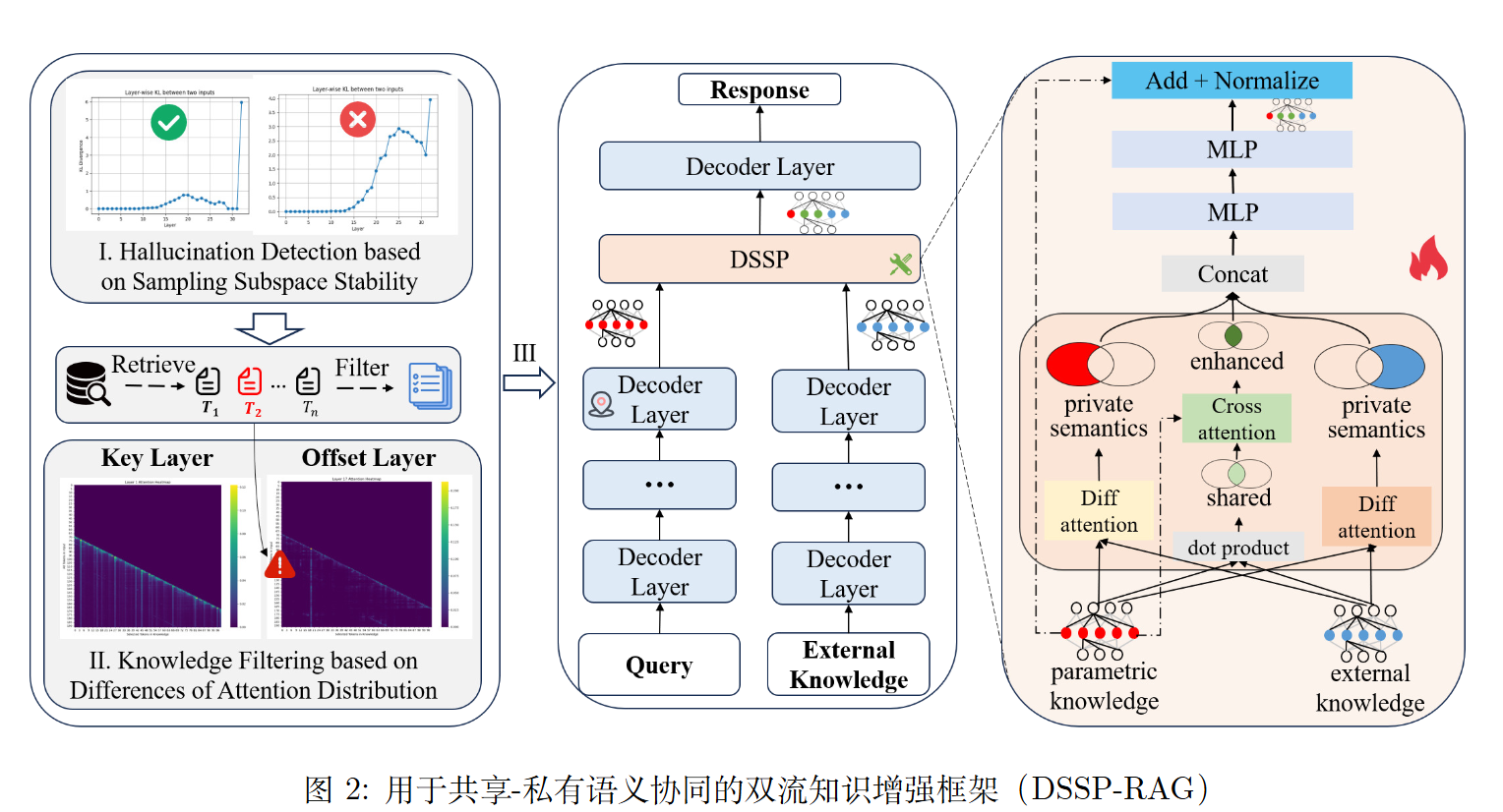
方法包含三个核心模块:无监督幻觉检测、知识过滤以及混合注意力机制(共享-私有语义协同)。
基于采样子空间稳定性的无监督幻觉检测
这个模块的作用是“判断何时需要引入外部知识”,避免盲目检索 。 作者利用了 LLM 的“认知不确定性”——面对语义相同但句法不同的提示词(Prompts)时,如果模型内部知识不足,其输出会表现出不一致 。
模型自动生成与原问题语义相同但表达不同的替代问题 $\hat{x}$ 。
使用 Jensen-Shannon 散度 (JSD) 来量化这对问题 $(x, \hat{x})$ 在模型各层的采样子空间(概率分布)之间的差异 。公式如下:
$$d(s _ {l}(\cdot|x),\hat{s _ {l}}(\cdot|\hat{x}))=JSD(s _ {l}(\cdot|x)||\hat{s _ {l}}(\cdot|\hat{x}))$$
其中,$s _ {l}$ 表示 LLM 在第 $l$ 层激活的采样子空间 。
如果散度 $d$ 超过预设的阈值 $\delta$(实验中 $\delta=1.0$),说明采样子空间不稳定,存在较高的幻觉风险,此时必须引入外部知识 。
基于注意力差异的外部知识过滤
检索到的外部知识可能有噪声,这个模块负责“去伪存真” 。 作者通过逐层剪枝实验发现,模型中的某些层(Key Layer / 关键层)负责提取与任务相关的全局语义,而另一些层(Offset Layer / 偏移层)则容易放大噪声 。
能量商 (Energy Quotient, EQ):作者通过计算偏移层($\alpha$)和关键层($\beta$)之间的注意力分布差异 $\Delta A=A _ {\alpha}-A _ {\beta}$,构建了一个过滤矩阵 EQ 。公式如下:
$$EQ _ {i}=\frac{exp(-\lambda\Delta A _ {i})}{\sum _ {j}exp(-\lambda\Delta A _ {j})}$$
$\Delta A _ {i}$ 越高,表示表示空间越不稳定,该特征更有可能是噪声($EQ _ {i}$ 越小);反之,$EQ _ {i}$ 越大则信息相关性越高 。
为了应对不同任务中噪声程度的变化,引入了基于语义熵差值的动态权重系数 $\epsilon$ 来进一步调整过滤效果 。
双流知识增强与混合注意力机制 (DSSP Module)
这是解决“上下文-记忆冲突”的核心。传统的自注意力机制难以区分内部知识($I$)和外部知识($\hat{D}$)中的共有部分和独有部分 。DSSP 提出了混合注意力机制,将其解耦为“共享语义”和“私有语义” 。
共享语义 (Shared Semantics):提取内外部知识的重合、一致部分 。通过点积计算相似度矩阵:
$$sim(I,\hat{D})=\varphi(\frac{(W _ {share}I)(W _ {share}\hat{D})}{\sqrt{d _ {k}}})$$
选取相似度最高的 Top-T 个 Token 后,利用交叉注意力(Cross-attention)将其融入内部知识流中得到 $U _ {enhance}$,从而增强生成的可靠性 。
私有语义 (Private Semantics):提取内外部知识中独有的、能填补对方空白的信息 。这里创新性地提出了差分注意力 (Differential Attention),即用单知识源的自注意力 $\tau(\cdot)$ 减去双流知识的交叉注意力 $\eta(\cdot)$,从而滤除共享部分:
$$U _ {private}=\mathcal{D} _ {attn}(X,Y)=\tau(X,X)-\eta(X,Y)$$
特征融合:最后,将增强的共享语义和内、外部的私有语义拼接,经过线性层动态调整权重,实现平滑融合 。
联合损失函数
为了让模型在训练时更好地适应外部知识并保持稳定,论文在常规的交叉熵损失之上,引入了两个正则化项 :
- 条件熵 $H(P(\hat{U}|I))$:用于调节预测的不确定性,使得模型能根据外部知识的可靠性动态调整置信度 。
- KL散度 $D _ {KL}$:限制外部知识带来的分布偏移,防止模型过度拟合或偏向错误信息 。
最终的损失函数为:
$$L=L _ {CE}+\mu H(P(\hat{U}|I))+\nu D _ {KL}$$
(实验表明最佳超参数为 $\mu=0.55$, $\nu=0.1$ )。
(6)Mitigating Hallucinations in Vision-Language Models through Image-Guided Head Suppression
motivation
作者发现,在解码生成文本的过程中,模型中某些特定的注意力头(Attention Heads)对图像 Token 的关注度极低(甚至在某些深层网络中不到 10%),而是把绝大部分注意力放在了文本 Token 上 。这种对视觉上下文的忽视是导致幻觉的直接原因 。
方法
第一步:计算对视觉 Token 的注意力 对于当前的文本查询 Token $q^i$,首先计算它与所有输入 Token 的未缩放注意力得分 $A _ {tot}$ :
$$A _ {tot} = q^i K^{iT}$$
然后,从中截取出专属于视觉 Token(长度为 $N_v$)的注意力片段 $A_v$ :
$$A_v = A _ {tot}[I _ {start}:I _ {end}]$$
**第二步:生成动态掩码$m_i$**接下来,SPIN 会计算每个头对视觉 Token 的累积注意力 $\sum _ {j=1}^{N_v} A_v[j]$ 。如果某个注意力头 $i$ 的视觉关注度排在所有头的前 $k$ 名(即表现良好),则保留它;否则,将其输出乘上一个惩罚因子 $\alpha$ 。
$$m_i = \begin{cases} 1 & \text{if } i \in \text{top-k}\left(\sum _ {j=1}^{N_v} A_v[j]\right) \ \alpha & \text{otherwise} \end{cases}$$
第三步:应用掩码最终的 SPIN 多头注意力计算会将这个掩码 $m_i$ 直接应用到每个头的输出上 :
$$\text{MHA} _ {Q,K,V,m} = \left(\text{concat} _ {i=1}^H (m_i h_i)\right)W_o$$
(7)The Impact of Negated Text on Hallucination with Large Language Models
深入探讨了一个在自然语言处理中常被忽视但非常关键的问题:大语言模型(LLMs)在处理包含否定词(如“不”、“从未”)的文本时,其检测和识别幻觉的能力会受到怎样的影响 。
作者提出了三个核心研究问题(RQs):
- RQ1:大模型在处理否定文本时,能否像处理肯定文本一样,准确区分幻觉和真实陈述?
- RQ2:在检测幻觉时,大模型的内部状态能否识别出由否定词引起的语义变化?
- RQ3:现有的干预策略(如提示词工程、知识编辑)能否改善大模型在否定文本中的幻觉检测表现?
方法
作者采用了一套系统性的方法,核心在于构建了专门的数据集 NegHalu,并结合内部状态观测(Logit Lens)和多种缓解策略进行实验 。
作者并没有从零开始收集数据,而是选取了三个现有的、针对肯定文本的权威幻觉检测数据集(HaluEval、BamBoo、SelfCheckGPT-WikiBio),并通过“后置否定(Post Negation)”将其重构为包含否定表达的新数据集 NegHalu 。
标签翻转(Label Flip)机制: 作者通过要求 GPT-4 模型在原句中仅插入一次“not”(避免双重否定),来强行反转句子的逻辑事实,从而改变其幻觉标签 。
- 逻辑翻转示例 1(真理变幻觉): 原始文本(True):拜仁慕尼黑是一支踢足球的球队。 否定后文本(Hallucinated):拜仁慕尼黑是一支不踢足球的球队。
- 逻辑翻转示例 2(幻觉变真理): 原始文本(Hallucinated):The Messenger 这部电影由 Michael Sheen 主演(事实上并非如此)。 否定后文本(True):The Messenger 这部电影不是由 Michael Sheen 主演的。
严格的双轮验证(Two-Round Verification): 为了保证生成的否定句符合现实常识且语法正确,作者设计了双轮过滤机制。第一轮用 GPT-4 生成 ;第二轮使用 3 个不同温度系数的 GPT-4 模型进行独立验证 。只有当 3 个模型都一致判定“逻辑否定有效”且“新标签正确(Pass, Pass)”时,该样本才会被保留 。最终保留了 1,950 个高质量样本,并经过了人类作者的二次人工复核 。
为了探究大模型为何在否定句上栽跟头,作者使用了 Logit Lens(逻辑透镜)技术来追踪模型在处理否定文本时的内部状态 。
通常,模型只有在最后一层(Final Layer)才会将隐藏状态映射为词汇表中的具体概率。Logit Lens 方法则是在模型的每一个中间层提取隐藏状态(Hidden States),并提前将其映射到词汇表空间(Vocabulary Space),从而观察模型在不同深度的网络中,对于预测下一个 token 的置信度变化 。
作者重点追踪了模型处理输入序列最后一个 token 和生成第一个判定 token 时的概率变化轨迹 。
作者测试了三种主流方法,试图修复大模型在否定文本上的缺陷:
上下文学习(In-Context Learning, ICL):测试 0-shot、2-shot、4-shot 设置,看提供正反面例子能否教会模型正确处理 。
思维链(Chain-of-Thought, CoT):要求模型在给出“是/否”幻觉的判断前,先一步步写出推理过程(Reasoning Step) 。
知识编辑(Knowledge Editing - AlphaEdit):作者使用了 AlphaEdit 技术来直接修改模型的参数。其核心数学思想是零空间约束(Null-Space Constraint) 。 在更新模型权重矩阵以纠正否定知识时,为了不破坏模型原有的肯定性事实知识,AlphaEdit 会将参数的更新量投影到保留知识的零空间中 。 如果将保留知识的协方差矩阵近似表示为 $C$,参数的更新量表示为 $\Delta W$,则优化目标受到如下约束:
$$\Delta W \cdot C \approx 0$$
这意味着更新方向与原有知识特征正交,从而实现在不遗忘旧知识的前提下,注入新的否定规则 。
结果
全面退化与“幻觉偏见”(回答 RQ1):
当文本从“肯定”变为“否定”时,几乎所有模型检测幻觉的准确率都出现了显著下降 。更严重的是,模型展现出了一种强烈的偏见:只要看到否定词,它们就倾向于盲目判定这句话是“幻觉” 。例如在 BamBoo 数据集上,否定文本被预测为幻觉的比例激增了 206.2% 。
模型内部对“否定”极度迟钝(回答 RQ2):
通过 Logit Lens 观察发现,即使否定词已经完全反转了句子的意思,模型在中间层和深层的概率转移曲线与没有否定词时几乎一模一样(只有极其微小的差别) 。这证明大模型在底层表示中,仅仅把“not”当成了一个普通的词汇 token,而未能将其理解为一个“逻辑取反运算符” 。
现有缓解策略效果有限(回答 RQ3):
In-Context Learning 和 CoT:效果极不稳定。有些模型反而因为加了提示词表现更差,证明这并不能触及模型对否定词理解缺失的根本痛点 。
知识编辑:虽然 AlphaEdit 在一定程度上减少了错误,但依然无法彻底解决系统性的“否定偏见” 。
(8)SHARP: Steering Hallucination in LVLMs via Representation Engineering
为了触发模型内部与幻觉相关的特征,作者构建了专门针对上述两种幻觉原因的数据集 $\mathcal{D}$ 。
将数据分为文本先验子集 $\mathcal{D}^{T}$ 和视觉-文本冲突子集 $\mathcal{D}^{C}$ 。给定图像 $v_i$ 和问题 $x_i$,让多模态模型生成答案 $\hat{y}_i$ 。随后,使用 GPT-4o-mini 对生成的答案与真实答案进行事实性打分(Correct/Incorrect) 。基于打分结果,将每个原因的子集进一步划分为“真实的(faithful/truth)”和“幻觉的(hallucinated)”两部分 。例如,对于原因 $m \in {T, C}$,我们得到了包含正确回答的数据集 $\mathcal{D} _ {faithful}^{(m)}$ 和包含幻觉回答的数据集 $\mathcal{D} _ {hallucinated}^{(m)}$ 。
在获得分类后的数据后,SHARP 利用对比分析来提取特征空间中的“指导向量”(Steering Vectors) 。
设 $h^{l^{\ast}}(v_i, x_i)$ 为模型在处理图像和问题时,在目标 Transformer 层 $l^{\ast}$ 处最后一个输入 token 的隐藏状态 。
对于每种幻觉原因 $m$,计算真实响应和幻觉响应的平均隐藏状态之间的差异 。提取向量 $\vec{v} _ {m}^{l^{\ast}}$ 的数学公式如下 :
$$\vec{v} _ {m}^{l^{\ast}} = \frac{\sum _ {(v _ {i},x _ {i}) \in \mathcal{D} _ {faithful}^{(m)}} h^{l^{\ast}}(v _ {i}, x _ {i})}{|\mathcal{D} _ {faithful}^{(m)}|} - \frac{\sum _ {(v _ {j},x _ {j}) \in \mathcal{D} _ {hallucinated}^{(m)}} h^{l^{\ast}}(v _ {j}, x _ {j})}{|\mathcal{D} _ {hallucinated}^{(m)}|}$$
- 这个向量 $\vec{v} _ {m}^{l^{\ast}}$ 代表了在表示空间中,区分“基于该原因产生的真实回答”与“幻觉回答”的平均判别方向 。
在实际推理过程中,SHARP 直接修改模型在生成每个 token 时的内部表示,以抑制幻觉 。
将针对文本先验($T$)和视觉冲突($C$)提取的两个指导向量进行线性组合 :
$$\vec{v} _ {adaptive}^{l^{\ast}} = \beta \cdot \vec{v} _ {T}^{l^{\ast}} + (1 - \beta) \cdot \vec{v} _ {C}^{l^{\ast}}$$
其中,$\beta$ 是一个控制两种幻觉原因权重的超参数 。
在自回归生成期间(针对所有位置 $t \ge |x_i|$ 的生成 token),在目标层 $l^{\ast}$ 将自适应向量注入到原始隐藏状态 $h _ {t}^{l^{\ast}}$ 中 :
$$h _ {steered, t}^{l^{\ast}} = h _ {t}^{l^{\ast}} + \alpha \cdot \vec{v} _ {adaptive}^{l^{\ast}}$$
其中,$\alpha$ 是控制整体干预强度的缩放因子 。注入后,模型使用修改后的 $h _ {steered, t}^{l^{}}$ 继续后续层的计算 。
(9)Mitigating Hallucinations in LM-Based TTS Models via Distribution Alignment Using GFlowNets
pass
(10)Mitigating Hallucinations in Large Vision-Language Models via Entity-Centric Multimodal Preference Optimization
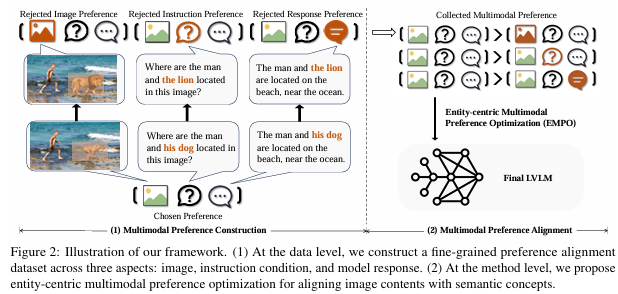
对三个模态都进行了“负样本(Rejected)”构造:
拒绝图像 ($v_l$):利用目标检测和 Stable-Diffusion-2 模型,把原图中的核心实体删除或替换成高频错误实体。这能强迫模型真正去看图,而不是靠猜 。
拒绝指令 ($q_l$):用 GPT 修改指令中的实体、属性或关系(例如把“狗在哪里”改成“猫在哪里”),保持句法结构一致但语义不同,生成困难负样本 。
拒绝回复 ($y_l$):将上述错误的图像和指令输入给 LVLM 诱导其生成错误回复,或者使用评估模型挑选出较差的回复 。
并引入细粒度实体加权 (Fine-grained Entity Weighting) ——引入多种模态条件会带来复杂的偏好组合,可能导致模型“作弊”(Reward Hacking) 。为了解决这个问题,作者在计算生成概率 $\log \pi(y|v, q)$ 时,对文本中的**关键实体 Token(即最容易产生幻觉的词)**赋予了更高的权重 $\alpha$ 。其公式如下:
$$\log \pi(y|v, q) = (1-\alpha) \sum _ {y_i \notin e} \log \pi(y_i|v, q, y _ {<i}) + \alpha \sum _ {y_i \in e} \log \pi(y_i|v, q, y _ {<i})$$
其中,$e$ 代表选定的关键实体,$y_i$ 是回复中的第 $i$ 个 token 。当超参数 $\alpha$ 较大时(例如实验中设为 0.7),模型在预测这些关键实体时如果出错,受到的惩罚会远大于普通的连词或介词 。
(11)Attention-guided Self-reflection for Zero-shot Hallucination Detection in Large Language Models
motivation
传统的幻觉检测方法(如 SelfCheckGPT)通常会对同一个问题进行多次采样(例如生成 5 次答案),然后比较这些答案是否一致 。如果一致性高,则认为不是幻觉。但这种方法有两个大问题:
- 计算成本极高:需要大模型运行多次 。
- 过于自信的错误:如果大模型对某个错误事实“深信不疑”,它每次采样的答案都会是一样的,从而骗过一致性检测 。
方法
设输入查询为由 $M$ 个 Token 组成的序列 $X = {x_1, x_2, …, x_M}$ 。 大模型记为 $f(\bullet)$,它对原始查询生成的初始答案为序列 $Y = f(X)$ 。
在大模型的自注意力层中,第 $l$ 层、第 $h$ 个注意力头的注意力矩阵计算公式为 :
$$A^{l,h} = \sigma\left(\frac{(X^{l-1}W_Q^{l,h})(X^{l-1}W_K^{l,h})^\top}{\sqrt{d_h}}\right)$$
这里 $\sigma$ 是 softmax 函数 。
为了衡量输入查询中第 $i$ 个 Token 对生成答案的贡献,作者提取了它对查询中最后一个 Token (即位置 $M$) 的注意力值 :
$$s_i^l = a _ {M,i}^l$$
由于大模型有多个层 (共 $L$ 层),作者测试了提取第一层、中间层、最后一层等不同策略 。实验证明,取所有层的平均值效果最好 :
$$s_i^{mean} = MEAN(a _ {M,i}^l | 0 < l \le L)$$
根据计算出的注意力贡献度评分集合 $S = {s_1, …, s_M}$,AGSER 选出得分最高的前 $k$ 个 Token(实验中默认取前 $2/3$ 的 Token )作为核心查询 (Attentive Query),剩下的组成非核心查询 (Non-attentive Query) :
$$X^{att} = \{x_i | s_i \in top_k(S)\}$$
$$X^{non_att} = \{x_i | s_i \notin top_k(S)\}$$
随后,将这两个截断的查询分别送入大模型,生成两个新的答案 :
$$Y^{att} = f(X^{att})$$
$$Y^{non_att} = f(X^{non_att})$$
接下来,使用文本相似度算法(如 Rouge-L)计算新答案与初始答案 $Y$ 之间的相似度(一致性得分) :
核心一致性得分:$r^{att} = Rouge(Y^{att}, Y)$
非核心一致性得分:$r^{non_att} = Rouge(Y^{non_att}, Y)$
如果核心一致性得分越小,且非核心一致性得分越大,说明模型产生幻觉的概率就越高 。因此,作者定义了最终的幻觉评估函数 $r$ :
$$r = r^{att} - \lambda r^{non_att}$$
(其中$\lambda$ 是平衡两者的超参数,通常设为1.0)
结论:计算出的 $r$ 值越低,代表大模型出现幻觉的程度越严重 。
(12)Unsupervised Hallucination Detection by Inspecting Reasoning Processes
motivation
很多基于不确定性的方法需要对同一个查询进行多次采样(生成多个回答)来计算不确定性,导致成本高昂且不适用于实时检测 。
一些基于内部状态的无监督方法(如 MIND),其标签主要依赖于表面或非事实相关的特征(例如是否匹配命名实体),这限制了模型在不同数据集和场景下的泛化能力 。
为了解决这些问题,作者提出了 IRIS (Internal Reasoning for Inference of Statement veracity) 框架。
方法
IRIS 认为,模型在思考和验证这个陈述时的状态,更能反映出它是否在产生幻觉 。
假设我们有一组陈述 $S = (s_1, …, s_n)$,我们的目标是判断每个 $s_i$ 是否为真 。
给定一个陈述 $s_i$,系统不仅让 LLM 判断真伪,还会通过思维链(Chain-of-Thought)提示,强制要求 LLM 给出一步步的推理过程 。假设 LLM 输出的验证回复为 $x_i$。系统会提取这个回复的上下文嵌入向量(Contextualized embeddings),记为 $\phi(x_i)$ 。具体来说,提取的是网络最后一层、最后一个 Token 的嵌入向量,将其作为后续分类器的输入特征。
由于是无监督学习,没有真实的人类标注标签(Ground Truth)。IRIS 的策略是将模型对自己推理结果的“置信度/不确定性”,转化为训练用的“软伪标签”(Soft Pseudolabel)。
对于每个嵌入向量 $\phi(x_i)$,系统生成一个范围在 $[0, 1]$ 之间的连续值标签 $\tilde{y}_i$ 。
这个值被归一化处理,$\tilde{y}_i = 1$ 代表模型极度确信陈述 $s_i$ 是正确的(非幻觉),而接近 0 则代表极度不确定或确信是错误的(幻觉)。
论文对比了基于概率熵(Entropy-based)和直接让模型用文字输出概率(Verbalized confidence)两种方式,发现直接让模型输出以数字表示的置信度,其校准效果更好,分布更合理 。
然后是训练轻量级分类器。因为“伪标签” $\tilde{y}_i$ 是 LLM 自己给自己打的分,必然包含大量的噪声(比如模型“盲目自信”或“过度怀疑”)。为了防止分类器对这些噪声标签过拟合,IRIS 引入了两个数学技巧来训练一个轻量级的多层感知机(MLP)。
技巧 A:软自举 (Soft Bootstrapping)
为了动态修正可能有偏差的伪标签,IRIS 在每个训练的 Mini-batch 中,不直接使用原始伪标签 $\tilde{y}_i$,而是结合分类器当前的预测值 $\hat{y}_i$,生成一个新的动态目标 $t_i$ 。
$$t_i = \beta\tilde{y}_i + (1-\beta)\hat{y}_i$$
- $\tilde{y}_i$ 是 LLM 给出的原始软伪标签。
- $\hat{y}_i$ 是分类器当前轮次的预测概率 。
- $\beta \in (0,1)$ 是一个权重系数 。这个公式的作用是让最终的训练目标在“模型的初始直觉”和“分类器学到的规律”之间寻找一个平衡,从而平滑噪声。
技巧 B:对称交叉熵损失 (Symmetric Cross Entropy Loss)
在计算损失时,仅仅让预测值靠近目标值是不够的。IRIS 采用了对称交叉熵损失函数作为整体优化目标 :
$$l_i = l _ {ce} + l _ {rce} = H(\hat{y}_i, t_i) + \phi H(t_i, \hat{y}_i)$$
这个公式由两部分组成 :
标准交叉熵损失 $H(\hat{y}_i, t_i)$:
$$H(\hat{y}_i, t_i) = t_i \log \hat{y}_i + (1-t_i) \log(1-\hat{y}_i)$$
这一项的目的是让分类器的预测 $\hat{y}_i$ 尽可能对齐我们上一步计算出的目标 $t_i$ 。(注:论文中以此形式表达交叉熵目标)。
逆交叉熵损失 $H(t_i, \hat{y}_i)$: 这一项的自变量位置互换了。它的核心作用是提供惩罚机制:如果分类器在某些潜在的错误目标上表现得过于自信(Overconfident),这一项就会产生很大的惩罚 。
$\phi$ 则是用来平衡这两种损失的超参数 。
结合这两个机制,分类器就能在没有完美人类标签的情况下,从 LLM 内部杂乱的验证信号中,鲁棒地学习到判断幻觉的有效边界 。
(13)Hallucination Detection in LLMs Using Spectral Features of Attention Maps
概述
将 LLM 的注意力机制视为图(Graph)中的信息流动,当信息流出现瓶颈或断裂时,模型往往会产生幻觉。
为了捕捉这种异常,作者提取了注意力图的图拉普拉斯矩阵(Graph Laplacian)的谱特征(特征值),并以此训练了一个轻量级的探测器(Probe)来分类文本是否为幻觉 。这个方法被命名为 LapEigvals。
方法
首先提取注意力矩阵。假设大模型有 $L$ 个 Transformer 层,每层有 $H$ 个注意力头。设生成的总 Token 数为 $T$。 对于任意第 $l$ 层和第 $h$ 个注意力头,其注意力矩阵记为 $A^{(l,h)} \in \mathbb{R}^{T \times T}$ 。
- 由于 Softmax 归一化,这是一个行随机矩阵(每行之和为 1) 。
- 由于自回归模型的因果掩码(Causal Mask),它是一个下三角矩阵(当前 Token 只能关注自己和之前的 Token,$j > i$ 时 $a _ {ij} = 0$) 。
在标准图论中,拉普拉斯矩阵定义为度矩阵(Degree Matrix)减去邻接矩阵。这里,邻接矩阵就是注意力矩阵 $A^{(l,h)}$ 。
$$L^{(l,h)} = D^{(l,h)} - A^{(l,h)}$$
因为这是一个有向图,作者区分了入度(In-degree)和出度(Out-degree):
- 入度:由于 Softmax 机制,每个 Token 接收到的总注意力总是 1,没有区分度 。
- 出度:衡量一个 Token 被后续多少个 Token 所关注。为了消除序列长度 $T$ 带来的影响,作者对出度矩阵 $D^{(l,h)}$ 进行了归一化,除以后续 Token 的数量(即出边的数量) :
$$d _ {ii}^{(l,h)} = \frac{\sum _ {u} a _ {ui}^{(l,h)}}{T - i}$$
其中 $i$ 是当前 Token 索引,$u$ 是后续 Token 索引 。这个 $D^{(l,h)}$ 是一个对角矩阵。
图的谱特征(特征值)能够总结图中的信息流动状态 。 非常巧妙的是,因为 $D^{(l,h)}$ 是对角矩阵,$A^{(l,h)}$ 是下三角矩阵,所以拉普拉斯矩阵 $L^{(l,h)}$ 也是一个下三角矩阵。
根据线性代数的基础知识,下三角矩阵的特征值就是它的对角线元素 。这极大地降低了计算复杂度!其特征值 $\lambda_i$ 的计算公式为:
$$\lambda_i = L _ {ii}^{(l,h)} = d _ {ii}^{(l,h)} - a _ {ii}^{(l,h)}$$
直观来看,这个特征值代表了:该 Token 被后续 Token 关注的平均程度,减去它对自己的关注度 。
然后,作者将这些特征值进行降序排序:
$$\tilde{z}^{(l,h)} = \text{sort}(\text{diag}(L^{(l,h)}))$$
为了综合全局信息,作者提取每个层和每个头中最大的 $k$ 个特征值(Top-$k$) :
$$z^{(l,h)} = [\tilde{z} _ {T-1}^{(l,h)}, \dots, \tilde{z} _ {T-k}^{(l,h)}]$$
随后,将所有层 $L$ 和所有头 $H$ 的 Top-$k$ 特征值拼接成一个极长的一维特征向量 $z \in \mathbb{R}^{L \cdot H \cdot k}$ 。 为了防止维度灾难并去除相关性,使用 PCA(主成分分析) 将其降维到 512 维 。最后,将降维后的特征输入到一个带有平衡类权重的**逻辑回归分类器(Logistic Regression)**中,用于预测该文本是否为幻觉 。
(14)EGOILLUSION: Benchmarking Hallucinations in Egocentric Video Understanding
pass
(15)Multi-Frequency Contrastive Decoding: Alleviating Hallucinations for Large Vision-Language Models
motivation
作者发现图像中频率信息的缺失(即忽略高频或低频信息)会放大这些语言先验,从而显著增加模型产生幻觉的概率 。
- 高频信息:通常代表图像中颜色剧烈变化的地方,如物体的边缘。
- 低频信息:通常代表颜色变化平缓的地方,构成了物体的基本形状和整体轮廓。
方法
基于上述发现,作者提出了 MFCD 方法。它的核心逻辑是:既然缺失高频或低频信息的图像会诱导模型产生“幻觉分布”,那么我们在生成文本时,只要把原始图像的输出分布,减去这些“幻觉分布”,不就能得到更真实的输出了吗?
首先,通过快速傅里叶变换(FFT)将原始输入图像 $V$ 转换到频域 : $F _ {i}(u,v)=FFT(f _ {i}(u,v))$
然后,分别应用高通滤波器(保留高频,去除低频)和低通滤波器(保留低频,去除高频):
$$\begin{cases}F _ {i}^{h}(u,v)=F_i(u,v)\cdot H _ {i}^{h}(u,v)\\ F _ {i}^{l}(u,v)=F_i(u,v)\cdot H _ {i}^{l}(u,v)\end{cases}$$
最后,通过逆傅里叶变换($FFT^{-1}$)将频域信号转回图像,得到移除低频信息的图像 $V_H$ 和移除高频信息的图像 $V_L$ :
$$\begin{cases}f _ {i}^{l}(u,v)=FFT^{-1}(F _ {i}^{l}(u,v))\\ f _ {i}^{h}(u,v)=FFT^{-1}(F _ {i}^{h}(u,v))\end{cases}$$
MFCD 则动态地对比三个分布 :
- 原始图像 $V$ 的输出分布(包含真实信号+轻微幻觉)。
- 图像 $V_H$(缺低频)的输出分布(放大了某种幻觉)。
- 图像 $V_L$(缺高频)的输出分布(放大了另一种幻觉)。
MFCD 的解码概率修改为以下形式 :
$$Y _ {t}\sim softmax[(1+\alpha _ {H}+\alpha _ {L})logit(Y _ {t}|V,X,Y _ {<t};M) - \alpha _ {H}logit(Y _ {t}|V _ {H},X,Y _ {<t};M) - \alpha _ {L}logit(Y _ {t}|V _ {L},X,Y _ {<t};M)]$$
说明:这里的 $\alpha_H$ 和 $\alpha_L$ 是超参数,控制惩罚两种幻觉分布的力度 。通过从原始 logit 中减去 $V_H$ 和 $V_L$ 对应的 logit,模型主动抑制了由频率信息缺失引发的语言先验偏差 。
直接相减可能会带来一个副作用:错误地惩罚了原本合理的词汇,或者奖励了极度不合理的词汇 。为了解决这个问题,作者引入了截断机制,构建了一个“合理词汇集” $\mathcal{V} _ {head}^{(t)}$ :
$$\mathcal{V} _ {head}^{(t)}={Y _ {t}\in\mathcal{V} : P(Y _ {t}|V _ {L},X,Y _ {<t};M) \ge \beta \max _ {\omega}P(\omega|V _ {L},X,Y _ {<t};M)}$$
在实际生成时,只有属于这个候选集里的 token 才会被保留计算,否则其概率直接置为 0,从而保证了生成的语句依然通顺且符合逻辑 。
在生成长句时,模型在不同时刻产生幻觉的倾向是不同的,固定参数不够灵活 。因此作者进一步提出了 MFCD-Plus,利用** Jensen-Shannon 散度 (JSD)** 动态计算原始分布与幻觉分布的相似度,并利用条件熵来衡量模型的不确定性 :
$$\alpha _ {H}^{(t)}=\alpha _ {H}/JSD(softmax(logit(V)), softmax(logit(V _ {H})))$$
$$\beta^{(t)}=\beta\times(1-e^{-H _ {LVLM}(Y _ {t}|V,X,Y _ {<t};M)})$$
这样,当模型倾向于产生幻觉时,惩罚力度会自动加大;当模型非常确信时,干扰则会降到最低 。
(16)How Much Do LLMs Hallucinate across Languages? On Realistic Multilingual Estimation of LLM Hallucination
pass
(17)Logit Space Constrained Fine-Tuning for Mitigating Hallucinations in LLM-Based Recommender Systems
pass
(18)Detecting LLM Hallucination Through Layer-wise Information Deficiency: Analysis of Ambiguous Prompts and Unanswerable Questions
motivation
论文特别关注上下文幻觉(Contextual Hallucinations),即当输入由于上下文模糊或信息不足而变为“不可回答的问题”时,模型仍会强行回答 。
现有方法的局限性:传统方法通常只分析模型的最终层输出或预测熵来评估模型置信度 。但作者发现,在神经网络中,信息的流动并不是单调增加或减少的 。只看最后一层会丢失模型内部不确定性的关键信号 。
核心假设:当模型缺乏处理其计算功能所需的信息时,就会在层间传输中表现为可用信息的缺乏(Information Deficiency),进而导致幻觉。
方法
为了捕捉跨层的信息动态,作者提出了一种称为逐层可用信息($\mathcal{L}I$)的指标 。
简单来说,它的计算逻辑是:对比“给定上下文”和“不给上下文”时,模型在每一层对问题预测的不确定性变化,然后将所有层的变化加总。
1. 定义每一层的预测条件熵 (Predictive Conditional Entropy)
假设模型有一个输入上下文 $C$(Context)和一个问题序列 $Q$(Question),模型具有多个层 $\mathcal{L}$ 。在第 $l$ 层,模型的隐藏状态会生成一个关于下一个 Token 的概率分布 $p_l(q_t|q _ {<t}, c)$ 。
在第 $l$ 层,如果给定上下文 $C$,预测问题的条件熵定义为:
$$H_l(Q|C) = \mathbb{E} _ {q \sim Q}[-\log_2 p_l(q_t|q _ {<t}, C)]$$
同样地,如果不给上下文(用空集 $\emptyset$ 表示),其条件熵定义为:
$$H_l(Q|\emptyset) = \mathbb{E} _ {q \sim Q}[-\log_2 p_l(q_t|q _ {<t}, \emptyset)]$$
2. 计算单层的信息贡献量 ($I_l$)
上下文 $C$ 在第 $l$ 层带来的可用信息量,等于“没有上下文时的不确定性”减去“有上下文时的不确定性”:
$$I_l(C \rightarrow Q) = H_l(Q|\emptyset) - H_l(Q|C)$$
3. 汇总所有层的预测 $\mathcal{L}$-Information ($\mathcal{L}I$)
最终的 $\mathcal{L}I$ 得分是将每一层的信息量 $I_l$ 累加起来,从而得到模型深度的整体评估:
$$\mathcal{L}I(C \rightarrow Q) = \sum _ {l \in \mathcal{L}} I_l(C \rightarrow Q)$$
对于数据集中的每个样本,模型进行两次前向传播(Forward pass):
- 路径 A(无上下文):仅输入问题,计算并记录每层的熵 $H_l(Q|\emptyset)$ 。
- 路径 B(有上下文):输入完整的上下文和问题,计算并记录每层的熵 $H_l(Q|C)$ 。
- 计算这两者的差值并在所有层上求和,即可得出 $\mathcal{L}I$ 。低 $\mathcal{L}I$ 分数意味着模型认为该问题缺乏足够的有用信息,即极大概率是“不可回答”或会导致幻觉的问题 。
(19)The Illusion of Progress: Re-evaluating Hallucination Detection in LLMs
motivation
文章指出,目前许多看似先进的幻觉检测方法,其优异表现很大程度上是建立在有缺陷的评估指标(如ROUGE)之上的,这给学术界和工程界制造了一种“进步的幻觉” 。
为什么 ROUGE 会带来“幻觉”?
过度依赖词汇重叠:ROUGE 指标最初是为文本摘要设计的,主要依赖生成的答案与标准答案之间的词汇重叠度来判断事实的一致性 。
高召回率,极低精确率:通过大规模的人类标注研究发现,ROUGE 虽然能抓取到大部分错误,但常常将使用了同义词或提供了更多有效背景信息的正确答案误判为幻觉,导致其精确率极低 。
存在长度偏见:ROUGE 对长答案存在系统性的惩罚 。论文通过控制实验证明,即使事实完全不变,仅仅让模型重复正确的信息导致文本变长,也会大幅降低 ROUGE 分数,甚至可以借此轻易操纵 ROUGE 的评估结果 。
为了揭露这一问题并寻找真实的幻觉检测水平,研究团队重新设计了评估框架:
引入新的黄金裁判(LLM-as-Judge):作者放弃了纯词汇匹配,转而使用 GPT-4o-Mini 作为事实正确性的语义裁判 。实验证实,这种评估方式与人类真实判断的对齐度(Agreement)极高,远超 ROUGE 。
广泛的基准测试:研究在 NQ-Open、TriviaQA 和 SQuAD 三个问答数据集上,测试了 Llama3.1-8B-Instruct 和 Mistral-7B-Instruct-v0.3 模型 。
重新评估现有方法:作者评估了当前主流的无监督幻觉检测方法,包括基于多次生成计算不确定性的方法(Perplexity, LN-Entropy, Semantic Entropy)和基于内部状态的检测方法(Eigenscore, LogDet) 。
引入有效秩 (eRank) 公式:论文还基于模型的隐藏状态引入并计算了 eRank,将其作为模型表示空间是否坍缩(从而引发幻觉)的衡量标准 。其核心数学定义如下 :
$$eRank = \exp(-\sum _ {k=1}^{m} p_k \log p_k)$$
其中,特征值的归一化概率分布计算为 :
$$p_k = \frac{\lambda_k}{\sum _ {j=1}^{m} \lambda_j}$$
这里的 $\lambda_k$ 是通过模型最终层或中间层的隐藏状态矩阵 $Z$ 计算出的协方差矩阵 $\Sigma = Z^T Z$ 的特征值。
关键发现一:幻觉检测的“性能暴跌”
当把评估指标从基于词汇的 ROUGE 切换为真正关注事实的 LLM-as-Judge 时,那些原本宣称表现优异的幻觉检测方法经历了灾难性的性能下滑 :
- 对于 Mistral 模型在 NQ-Open 数据集上,Perplexity 方法的 AUROC分数暴跌了 45.9% 。
- 基于内部状态的 Eigenscore 和 eRank 等复杂方法,也分别出现了高达 30.4% 和 36.4% 的性能断崖式下跌 。
关键发现二:颠覆认知的“长度法则”
在深挖失败原因时,论文提出了一个极其简单却颠覆性的发现:回答的长度(Response Length)本身就是一个极为强大的幻觉预测信号 。
- 幻觉雪球效应:包含幻觉的错误回答通常明显比正确回答更长,且长度变化更大 。这往往是因为模型在试图掩盖信息缺失或胡编乱造时,为了维持字面连贯性而产生了“雪球效应”,导致错误不断累积和文本膨胀 。
- 极简指标击败复杂算法:作者构建了三个毫无技术门槛的长度指标:
Len(单次生成的文本长度)、Mean-Len(多次生成的平均长度)和Std-Len(长度的标准差) 。实验结果令人惊讶:简单的Mean-Len甚至直接追平或击败了 Eigenscore 和 LN-Entropy 等复杂的数学和内部计算方法 。
控制变量实验(探究因果性)
为了探求“长度”和“幻觉”之间究竟是相关关系还是因果关系,研究人员进行了控制实验:
- 啰嗦本身就会诱发幻觉:如果在 Prompt 中强制要求模型生成更长、更详细的答案(即使初始事实是正确的),模型产生事实偏移和引入错误信息(即幻觉)的概率会显著增加 。
- 模糊的输入是最大的推手:相比于在问题中强行塞入误导性的上下文(Distractor Context),如果把问题改写得更加含糊不清(Ambiguous Input),会导致模型的回答长度激增,并引发更严重的准确率崩塌 。
(20)A Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Outputs
作者提出在冻结的LLM外部附加一个基于Transformer架构的轻量级“插件”(即 UHead),专门用来量化模型在生成特定声明(claim)时的不确定性,从而精准捕捉幻觉。
核心特征提取
UHead 会从 LLM 的每一层($L$)和每一个注意力头($Q$)中,提取当前 token $t_i$ 对前 $k$ 个token的注意力权重,并将其展平为一个向量 :
$$F_{att}(t_i) = {\alpha_{i, i-j}^{ql}}_{j,q,l}^{k,Q,L}$$
其中 $\alpha$ 是注意力权重 。
作者发现,仅需回顾非常少的前置 token($1 \le k \le 5$)就能获得最佳效果,避免了特征空间的爆炸 。
模型生成词汇时的概率分布直接反映了它的条件置信度 。UHead 会提取当前步预测中,概率最高的 $m$ 个 token 的对数概率 :
$$F_{prob}(t_i) = {\log P(t|x, t_{<i}) \mid t \in top_m(P(\cdot|x, t_{<i}))}$$
最终,每个 token $t_i$ 的特征由上述两部分拼接而成 :
$$F(t) = F_{att}(t) \circ F_{prob}(t)$$
UHead 的网络架构与计算流程
提取出特征后,UHead 会通过一个基于 Transformer 的小型网络来计算特定声明是幻觉的概率 。假设提示词为 $x$,生成的文本中包含一个原子声明 $c$。
步骤 1:Token 级别特征投影 (Token-level feature extraction) 首先,将拼接好的特征向量通过一个全连接层(FC)进行降维,使其维度与 UHead 内部的 Transformer 编码器维度一致 :
$$\tilde{f}t = FC{proj}(F(t))$$
步骤 2:特定声明的上下文标记 (Claim-specific contextualization) 为了让模型将注意力集中在特定的声明 $c$ 上,作者引入了一个可训练的“声明标记嵌入”(Claim-marking embedding)$E$ 。如果某个 token 属于该声明,就把 $E$ 加到它的特征上 :
$$\tilde{f}_{t,c} = \tilde{f}_t + E \cdot \mathbb{1}(t \in c)$$
(注:$\mathbb{1}(\cdot)$ 是指示函数,属于声明 $c$ 时为 1,否则为 0 )
步骤 3:Transformer 编码 (Transformer encoding) 将带有标记的特征序列输入到一个多层 Transformer 编码器中,得到融合了上下文信息的隐藏状态序列 $H_c$ :
$$H_c = \text{Transformer}(\tilde{F}_c)$$
步骤 4:池化与表示 (Pooling and representation) 为了得到整个声明的单一表示向量,对声明 $c$ 包含的所有 token 的隐藏状态进行掩码平均池化(Masked average pooling):
$$h_c = \frac{1}{|c|} \sum_{t \in c} h_{t,c}$$
步骤 5:分类输出 (Classification) 最后,将声明的表示向量 $h_c$ 输入到一个带有 Dropout 正则化的两层多层感知机(MLP)中,并通过 Sigmoid 函数输出该声明是幻觉的不确定性得分$u_c$:
$$u_c = \sigma(MLP_{classifier}(h_c))$$
$u_c$ 的值越接近 1,说明该声明是幻觉的可能性越大 。
模型的训练 (Training)
在训练 UHead 时,基础 LLM 的参数是完全冻结的,以保证其生成行为不发生改变 。UHead 使用标准的二元交叉熵损失函数(Binary Cross-Entropy Loss)进行训练 :
$$\mathcal{L} = -\mathbb{E}_{(x,y,c,v)\sim\mathcal{D}}[v \log u_c + (1-v) \log(1-u_c)]$$
这里$v$是真实标签(如果是幻觉则$v=1$,真实事实则$v=0$)。
为了低成本、大规模地获取训练数据,作者设计了一个自动数据生成流水线 :
- 让一个小体积的开源 LLM(如 Mistral)生成关于名人传记等领域的回答 。
- 使用更强大的模型(如 GPT-4o)将回答拆解成一个个独立的原子声明(Atomic Claims)。
- 再次使用 GPT-4o 对这些声明进行真实性标注(支持、不支持或未知)。