In-Place Test-Time Training
(ICLR 2026 Oral)
字节SEED团队。
motivation
“先训练后部署”的瓶颈:当前的大语言模型普遍采用静态的范式,这意味着模型一旦部署,其权重就固定了,无法根据现实世界中源源不断的新信息进行动态调整 。
传统 TTT 方法的障碍:测试时训练(Test-Time Training, 简称 TTT)机制允许模型在推理时更新一小部分参数(即“快权重”),但在 LLM 生态中落地时面临三大障碍 :
- 架构不兼容:现有方法通常引入全新的特殊层来取代注意力机制,这要求极其昂贵的“从头预训练”过程,难以直接应用于现有的百亿参数模型 。
- 计算效率低下:传统的 TTT 更新是逐 Token(per-token)进行的,这种串行操作极大地限制了现代硬件(如 GPU/TPU)的大规模并行计算能力 。
- 优化目标不匹配:过去 TTT 多采用通用的“重建(reconstruction)”目标,但这并没有专门针对自回归语言模型的“下一个 Token 预测(Next-Token Prediction)”任务进行优化 。
为了克服上述障碍,研究团队提出了 In-Place TTT 框架,包含三大核心设计:
- 原地(In-Place)自适应改造:该框架没有引入新的网络层,而是巧妙地将 Transformer 中无处不在的多层感知机(MLP)模块的最终投影矩阵($W _ {down}$)重新用作可适应的“快权重” 。这种“即插即用”的设计不需要修改模型架构,保留了预训练权重的完整性,避免了从头重训的巨大成本 。
- 高效的块状(Chunk-Wise)更新机制:该方法放弃了低效的逐 Token 更新,转而采用可扩展的块状更新规则 。因为这种设计是对注意力机制的补充而非替代,所以可以使用更大的文本块,从而在现代加速器上实现极高的计算吞吐量,且完美兼容上下文并行(Context Parallelism)技术 。
- 对齐语言模型的优化目标(LM-Aligned Objective):团队引入了一个具有理论支撑的新目标,明确与“下一个 Token 预测(NTP)”任务对齐 。通过使用一维卷积(Conv1D)和投影矩阵将未来 Token 的信息融入目标值($V = Conv1D(X_0)W _ {target}$),该目标会鼓励快权重存储对预测未来文本真正有用的上下文信息,这比简单的重建目标要高效得多 。
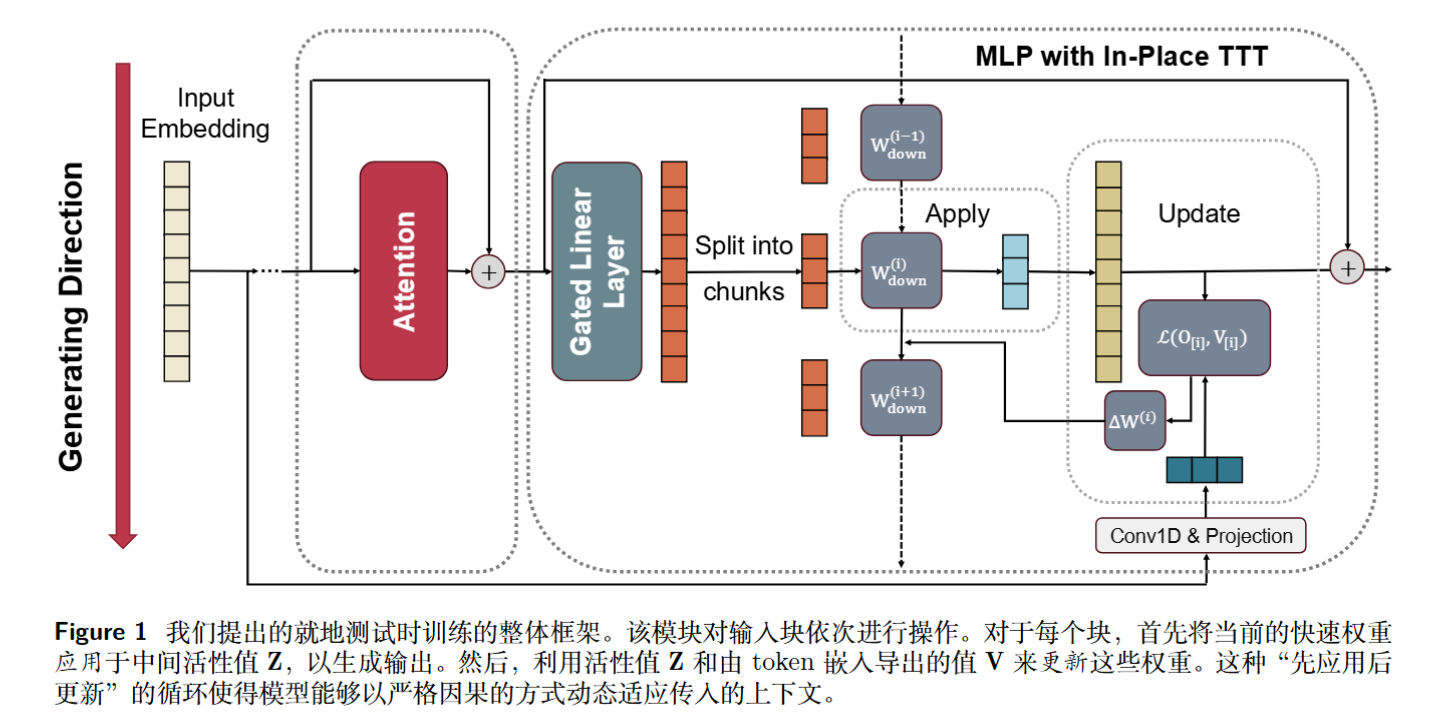
方法
原地自适应:重用 MLP 模块 (In-Place Adaptation)
在现代 Transformer 架构中,最常见的 MLP 变体是门控 MLP(Gated MLP)。给定隐藏层表示 $H$,其标准的前向传播公式为 :
$$O = (\phi(HW _ {gate}^\top) \odot (HW _ {up}^\top))W _ {down}^\top$$
- H为隐藏表示
In-Place TTT 框架将 $W _ {up}$ 和 $W _ {gate}$ 视为在预训练阶段冻结的“慢权重(Slow Weights)”,而将最后的投影矩阵 $W _ {down}$ 视作可以在推理时动态更新的“快权重(Fast Weights)” 。这样就不需要修改原本的模型结构。
高效的块状更新机制 (Chunk-Wise Updates)
为了解决逐个 Token 更新带来的低效问题,该框架将输入序列划分为多个块(Chunks)进行处理 。
设中间激活值为 $Z = \phi(HW _ {gate}^\top) \odot (HW _ {up}^\top)$。我们将激活值 $Z$、目标值 $V$ 和输出 $O$ 划分为 $k$ 个大小为 $C$ 的非重叠块。对于第 $i$ 个块,记为 $Z _ {[i]}, V _ {[i]}, O _ {[i]}$ 。
初始快权重设为 $W _ {down}^{(0)} = W _ {down}$。对于序列中的每一个块 $i$,交替执行以下两步 :
步骤一:应用 (Apply Operation)
使用当前的快权重处理当前块的特征,得到输出:
$$O _ {[i]} = Z _ {[i]} (W _ {down}^{(i)})^\top$$
步骤二:更新 (Update Operation)
使用梯度下降法更新快权重,使其能够记住当前块的信息(其中 $\eta$ 为学习率,$\mathcal{L}$ 为损失函数):
$$W _ {down}^{(i+1)} = W _ {down}^{(i)} - \eta \nabla _ {W} \mathcal{L}(Z _ {[i]}(W _ {down}^{(i)})^\top, V _ {[i]})$$
对齐语言模型的目标函数 (LM-Aligned Objective)
这是论文中最核心的理论贡献。传统的 TTT 方法通常使用简单的“重建”目标,即让模型记住当前的 Token(目标值设为当前 Token 的嵌入)。但这并不符合语言模型的核心任务——下一个 Token 预测(Next-Token Prediction, NTP) 。
为了让快权重能够压缩并存储对预测未来有用的信息,论文设计了一个包含未来 Token 信息的目标值 $\hat{V}$ :
$$\hat{V} = Conv1D(X_0)W _ {target}$$
其中,$X_0$ 是原始 Token 的嵌入,$Conv1D(\cdot)$ 是一维卷积操作(用于捕捉局部的未来上下文),$W _ {target}$ 是一个可训练的投影矩阵 。
为了简化计算,损失函数 $\mathcal{L}$ 被定义为负的内积相似度(即促使激活值与目标值尽可能对齐):
$$\mathcal{L}(\cdot, \cdot) = - \langle \cdot, \cdot \rangle_F$$
将这个简单的损失函数代入前面的“块状更新”梯度公式中,得到了一个极为优雅且易于计算的更新规则 :
$$W _ {down}^{(i)} = W _ {down}^{(i-1)} + \eta \hat{V} _ {[i]}^\top Z _ {[i]}$$
这个公式表明:每次更新,实际上就是把当前块的中间激活 $Z _ {[i]}$ 和包含未来信息的 $\hat{V} _ {[i]}$ 做外积,然后累加到原有的投影矩阵中。
理论分析
想象模型正在阅读一段文本,在之前的上下文中,出现过一个键值对(Key-Value pair):$(x _ {t^\ast}, x _ {t^\ast+1}) = (k^\ast, v^\ast)$,比如”哈利”($k^\ast$) 后面跟着”波特”($v^\ast$) 。
现在,模型读到了当前位置 $n$($n > t^\ast$),当前的查询 Token $x_n = k^\ast$(模型再次读到了“哈利”)。为了完成感应任务,模型必须正确预测下一个 Token 是 $x _ {n+1} = v^\ast$(即预测出“波特”)。
核心假设
作者首先提出了两个假设:
假设1:词嵌入的近似正交性 (Approximate Orthogonality of Embeddings)
- 不同的 Token 之间,它们的词嵌入向量(Embedding)几乎是正交的,即内积极小:$|e _ {w_i}^\top e _ {w_j}| \le \epsilon$。
- 同一个 Token 自身的词嵌入向量有足够大的模长:$||e _ {w_i}||^2 \ge c _ {norm}^2 > 0$。
假设2:键-查询对齐 (Key-Query Alignment)
- 在当前查询位置 $n$(哈利)和过去出现的键位置 $t^\ast$(哈利),由于它们是同一个词,它们的中间激活值是高度对齐的:$\mathbb{E}[z _ {t^\ast}^\top z_n] = c _ {align} > 0$。
- 对于上下文中其他无关的 Token 位置 $t$,它们与当前查询的期望相关性为 0:$\mathbb{E}[(V_t Z_t^\top)Z_n] = 0$。
证明
快权重 $W _ {down}$ 在吸收了历史上下文后,发生了更新量 $\Delta W _ {down}$ 。 这个更新量会直接改变当前位置预测任意词汇 $w$ 的逻辑值(Logit,即输出概率前的得分),记为 $\Delta l_n[w]$ 。
根据 TTT 的更新规则,逻辑值的变化量可以展开为 :
$$\Delta l_n[w] = \lambda _ {lr} \sum _ {t \in prior} (e_w^\top v_t) (z_t^\top z_n)$$
(其中 $\lambda _ {lr}$ 是学习率,$v_t$ 是我们设定的目标值,$z_t$ 和 $z_n$ 分别是历史和当前的激活值)
根据假设 2,除了 $t^*$(也就是上一次出现“哈利”的位置)之外,其他位置的期望值都是 0 。所以对上面公式求期望,可以极大地简化为只剩下一项:
$$\mathbb{E}[\Delta l_n[w]] = \lambda _ {lr} \cdot \mathbb{E}[(e_w^\top v _ {t^}) \cdot (z _ {t^}^\top z_n)]$$
接下来,我们将分别代入两种不同的目标(Target)$v _ {t^*}$ 来观察结果。
情境 A:使用传统的“重建目标”(Reconstruction Target)
传统的 TTT 试图记住当前 Token,所以目标值被设定为当前 Token 的词嵌入:$v _ {t^} = e _ {x _ {t^}} = e _ {k^*}$(目标是“哈利”)。
我们来看看这对预测正确答案 $v^*$(波特)的逻辑值有什么影响 :
$$\mathbb{E}[\Delta l_n[v^]] = \lambda _ {lr} \cdot \mathbb{E}[(e _ {v^}^\top e _ {k^}) \cdot (z _ {t^}^\top z_n)]$$
由于 $k^$(哈利)和 $v^$(波特)是两个不同的词,根据假设 1(不同词的内积极小,$\le \epsilon$),我们可以得出结论 :
$$|\mathbb{E}[\Delta l_n[v^*]]| \le \lambda _ {lr} \cdot \epsilon \cdot c _ {align}$$
结论 A: 传统目标对提升正确答案的概率毫无帮助(变化量极小,受制于 $\epsilon$)。它只是让模型记住了上下文里有个词,但没有建立上下文之间的因果预测关系。
情境 B:使用“语言模型对齐目标”(LM-Aligned Target)
作者提出的新方法,将目标值设定为下一个 Token 的词嵌入:$v _ {t^} = e _ {x _ {t^+1}} = e _ {v^*}$(目标是“波特”)。
同样计算对正确答案 $v^*$ 的逻辑值影响:
$$\mathbb{E}[\Delta l_n[v^]] = \lambda _ {lr} \cdot \mathbb{E}[(e _ {v^}^\top e _ {v^}) \cdot (z _ {t^}^\top z_n)]$$
此时出现了 $e _ {v^}^\top e _ {v^}$,也就是同一个词的内积。根据假设 1,它的值 $\ge c _ {norm}^2$ :
$$\mathbb{E}[\Delta l_n[v^*]] \ge \lambda _ {lr} \cdot c _ {norm}^2 \cdot c _ {align}$$
并且,对于任何错误的答案 $w \ne v^$,因为 $w$ 和 $v^$ 不同,其逻辑值变化仍然被压制在微小的 $\epsilon$ 级别 :
$$|\mathbb{E}[\Delta l_n[w]]| \le \lambda _ {lr} \cdot \epsilon \cdot c _ {align}$$
结论 B: 论文提出的目标能够在数学期望上绝对保证提升正确下一个 Token 的逻辑值,同时保持其他错误 Token 的逻辑值基本不变 。
工程实现
因为最终的权重更新规则非常简单(就是一系列外积的累加):
$$W _ {down}^ {(i)} = W _ {down}^ {(0)} + \eta \sum _ {j=1}^ {i} \hat{V} _ {[j]}^ \top Z _ {[j]}$$
这种结合律(Associative)特性使得它极其适合现代 GPU/TPU 上的“上下文并行” 。在实现时,可以通过极高效率的并行前缀和(Parallel Prefix Sum)算法,一次性计算出所有块的更新量 $\Delta S_i$ :
$$\Delta S_i = \sum _ {j=1}^{i-1} \Delta W_j$$
然后再将这些更新量应用到各个块的特征计算中 。这既保证了严格的因果时序(不会泄露未来信息),又彻底释放了硬件的并行计算能力 。