Detecting Contextual Hallucinations in LLMs with Frequency-Aware Attention
(ICML 2026)
motivation
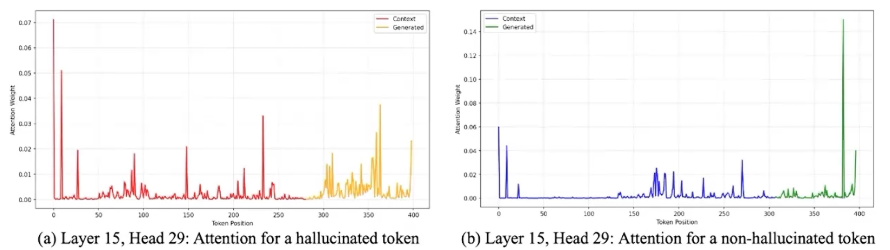
幻觉检测常常使用attention mass或者熵,然而这些方法缺乏细粒度。如下图是熵相同的。
方法
作者提出,当模型生成“有依据的(Grounded)”词元时,它的注意力分布通常是平滑且连贯的(类似于低频信号);而当模型开始“胡说八道(Hallucinate)”时,它无法在上下文中找到明确的对应信息,导致注意力在不同的上下文词元之间快速跳跃、震荡,表现出碎片化和不稳定的行为。
将注意力权重序列视为一个一维离散时间信号。使用高通滤波器(High-pass filters)提取出该信号中的高频成分(代表快速的局部波动)。分为指向上下文的注意力、已生成词元的注意力。
为了量化它的“剧烈程度”,作者使用了 $l_2$ 范数(在信号处理中对应于信号的“能量”)来汇总高频波动的幅度。(L2范数的平方是能量,且具有帕塞瓦尔定理:在时域中计算的能量等于频域中的能量)
将其输入到一个非常轻量级的线性分类器(例如逻辑回归)中,输出当前词元是否为幻觉。
只输入能量,不输入高频信号。
实验
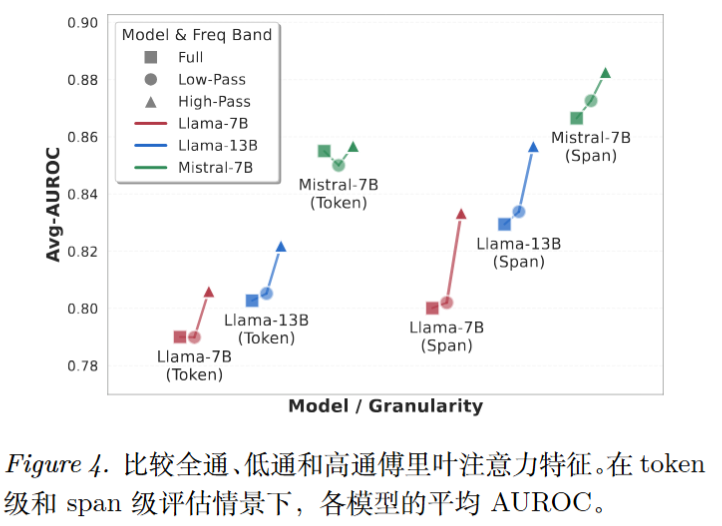
包括 LLaMA-7B-Chat、LLaMA-13B-Chat 和 Mistral-7B-Instruct,数据集RAGTruth和HalluRAG。
数学证明
作者想要证明,注意力权重在相邻词元之间的波动程度(即相邻差值的平方和 $\mathbb{E}[R_t]=\sum(\alpha_{t,j+1}-\alpha_{t,j})$,代表高频能量)存在一个下界,且这个下界随着潜在语义话题数 $K$ 的增大而单调递增。
作者分为了三步走逻辑。
第一步:话题切换的概率与 $K$ 的关系
假设输入上下文中的每一个词元(Token),都是模型从 $K$ 个潜在的“语义话题”(可以理解为高斯混合模型 GMM 中的 $K$ 个聚类中心)中随机抽取出来的。
因为是独立同分布的随机抽取,相邻的两个词元(第 $j$ 个和第 $j+1$ 个)碰巧属于同一个话题的概率是 $1/K$。那么,它们属于不同话题(即发生话题切换)的概率就是 $1 - 1/K$。
当模型处于“幻觉”状态时,它无法在上下文中找到确切的依据,脑子里的思绪是散乱的,相当于 $K$ 非常大(比如一会儿想到苹果,一会儿想到宇宙)。$K$ 越大,$1 - 1/K$ 就越接近 1。这意味着模型在阅读上下文时,几乎每看相邻的两个词,潜意识里的“语义频道”都在发生剧烈的切换。
第二步:语义切换导致“原始打分”的剧烈波动
大模型在生成当前词元时,会用一个查询向量(Query, $q_t$)去和上下文词元的键向量(Key, $k_j$)做内积,算出一个没经过 Softmax 的原始得分(Logits),我们记作 $s_{t,j}$。
假设不同的语义话题在向量空间中是相互分离的(至少相隔距离 $\Delta$)。当相邻两个词元发生“话题切换”时,由于它们在空间中距离很远,它们与 $q_t$ 计算出的内积得分也会出现一个巨大的落差(记作 $\Delta s = s_{t,j+1} - s_{t,j}$)。
作者证明了相邻Logits差值的平方期望 $\mathbb{E}[(s_{t,j+1} - s_{t,j})^2]$ 的下界包含了 $(1 - 1/K)\Delta^2$ 这个项(直接代入了第一步的切换概率)。
$$
\mathbb{E}[(s_{t,j+1} - s_{t,j})^2] \ge 2\sigma^2||u||_2^2 + (1 - \frac{1}{K})\Delta^2
$$
这说明,语义上的“左右横跳”(高概率的话题切换),被忠实地转化成了模型底层打分数值的“悬崖式跌宕”。
第三步:Softmax 无法抹平这种数值波动
虽然底层打分(Logits $s$)波动很大,但我们知道注意力机制最后会过一个 Softmax 函数(把绝对分数压缩成和为1的相对百分比)。这个压缩过程会不会把波动抹平,让表面上的注意力权重 $\alpha$ 看起来很平滑呢?
设相邻两个词元的最终注意力权重为 $\alpha_{t,j}$ 和 $\alpha_{t,j+1}$,它们的权重之和为 $m$。作者推导出:
$$\alpha_{t,j+1} - \alpha_{t,j} = m \tanh(\frac{\Delta s}{2})$$
而$|\tanh(x)| \ge \frac{|x|}{2}$,故$|\Delta \alpha| \ge m \cdot \frac{|\Delta s|}{4}$。
会有一个下界来保证仍存在数值波动。