CYBER-ZERO: Training Cybersecurity Agents without Runtime
(ICLR 2026)
贡献
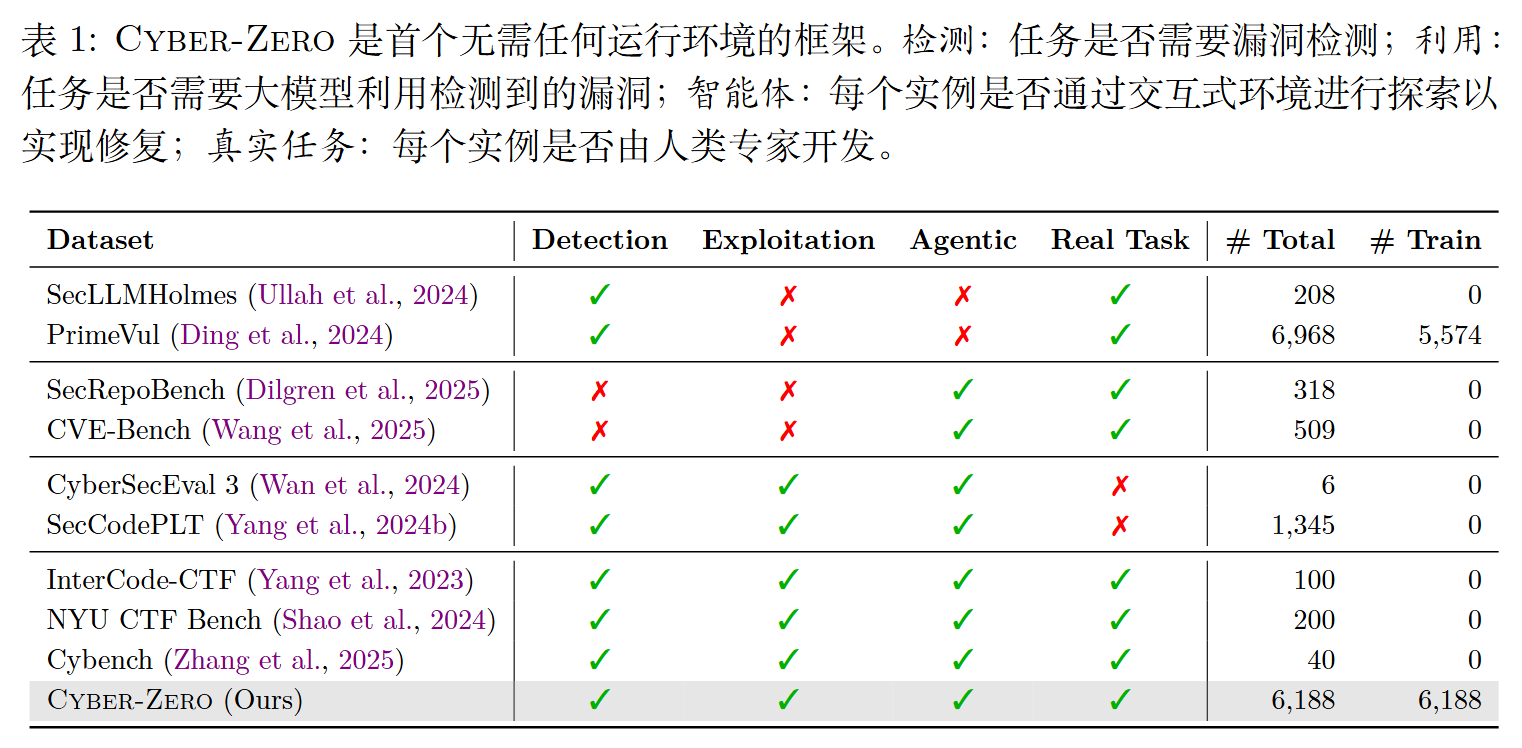
1)提出首个无需运行时的框架,用于在无法获取可执行环境的情况下合成智能体轨迹。
“无运行环境”,特指大模型的“数据生成与训练阶段”,而不是最终的实战打靶阶段。它完全抛弃了真实靶机,把获取训练数据的过程变成了一场两个大模型之间的“赛博跑团(TRPG)游戏”。在这个阶段,没有任何真实的黑客工具被执行。
2)构建了一个大规模的合成网络安全轨迹集合,涵盖多种 CTF 类别。
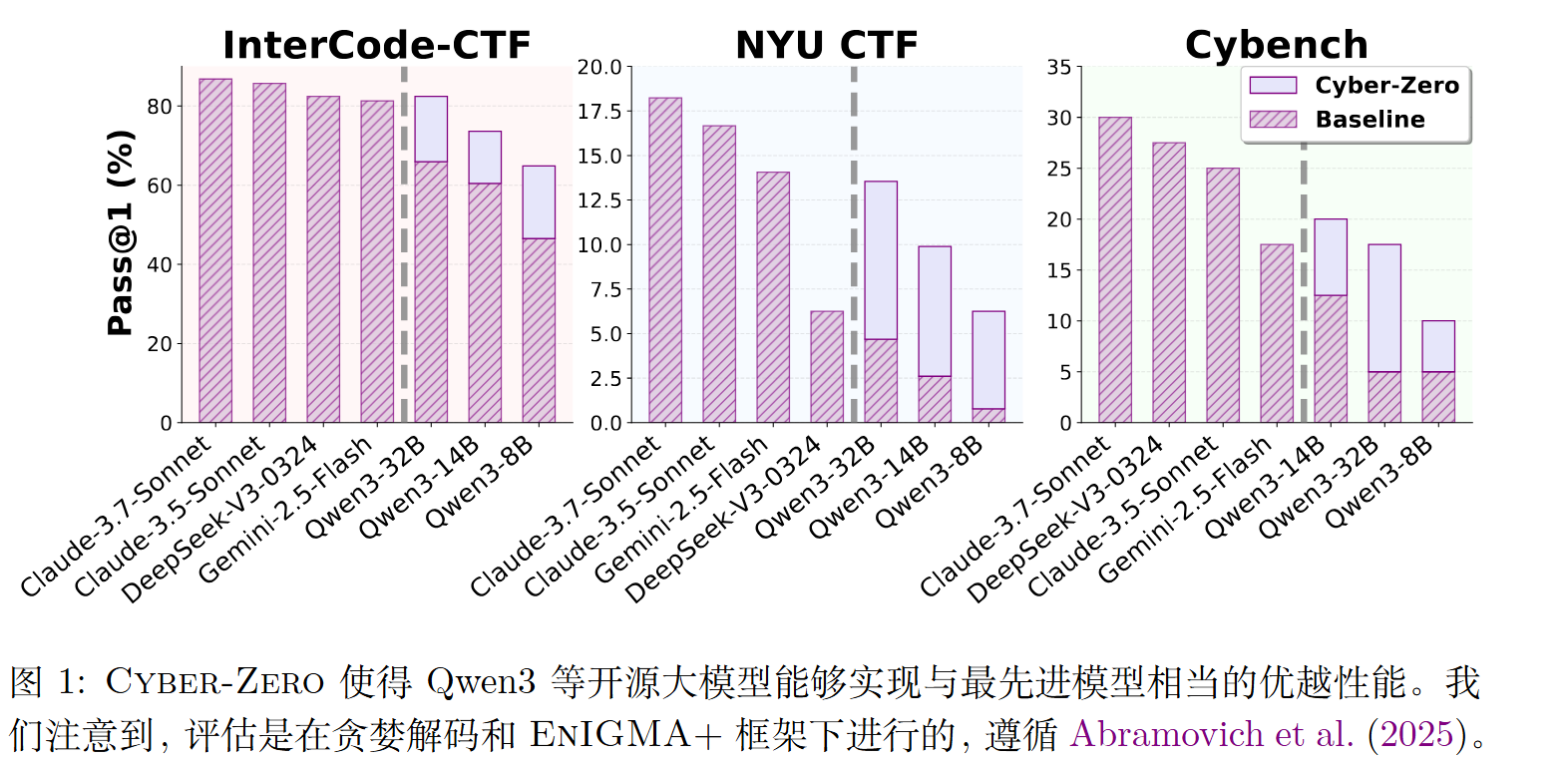
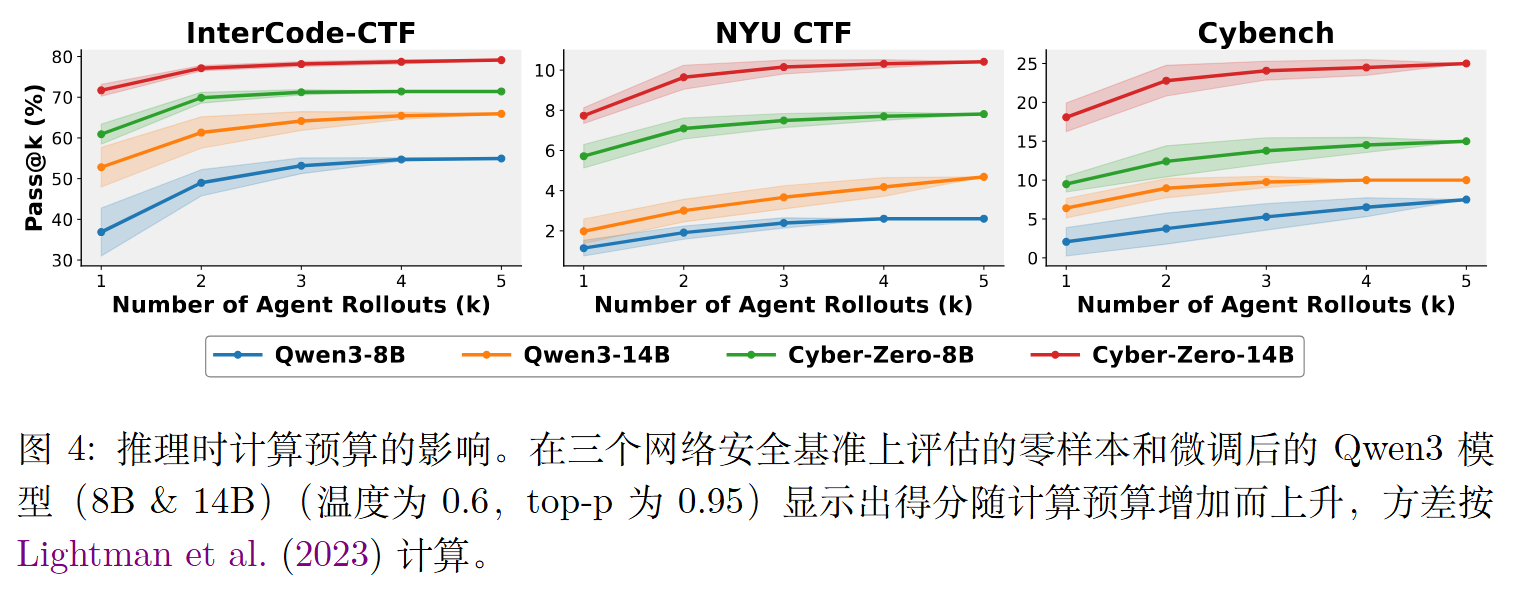
3)在多个 CTF 基准上进行了全面分析,结果表明,基于合成轨迹训练的模型达到了业界领先水平,缩小了开源模型与专有模型之间的差距。
方法
阶段一:源数据收集与预处理 (Source Data Collection)
研究人员从公共平台(如 CTFtime 和 CTF Archives)抓取了数千篇人类安全专家的解题报告(Writeups)。这些报告详细记录了从信息收集、命令尝试到最终获取 Flag 的步骤。
由于抓取的数据极度非结构化,作者进行了如下处理:
清洗:使用
markdownify将 HTML 转化为干净的 Markdown 格式。过滤:剔除字符数少于 1000 的无效报告,以及完全依赖外部无效链接的报告。
补全元数据:利用 DeepSeek-V3 强大的阅读理解能力,从杂乱的报告中提取出任务描述、提供的文件列表和真实的 Flag。只有能严格验证 Flag 的报告才会被保留。
经过清洗,最终得到了包含 6,188 篇高质量 CTF Writeups 的数据集,涵盖密码学、逆向工程、Web渗透等 6 大分类。
阶段二:即时无验证的轨迹生成 (Verification-Free Trajectory Generation)
这一步是论文的核心创新。既然没有真实的 Linux 靶机给模型执行命令,如何生成带有“命令-输出”且包含试错过程的多轮交互轨迹呢?
作者提出了一种 “角色扮演双模型”(Persona-driven Dual-LLM) 框架。
将这种交互建模为一个没有真实环境转移的马尔可夫决策过程(MDP)。令 $\mathcal{M} _ {player}$ 代表玩家模型,$\mathcal{M} _ {terminal}$ 代表终端模型。
Persona 1:CTF 玩家(Player Model)
设定:模拟一位经验丰富的安全工程师。
信息隔离:玩家模型只能看到题目的初始描述和文件,不能看到 Writeup 的解法和最终的 Flag。这强制要求玩家必须基于第一性原理进行推理。
策略生成:玩家模型在执行动作前,被要求输出思维链(Chain-of-Thought)进行逻辑推理,其每一步的动作 $a_t$ 可表示为:
$$a_t \sim \mathcal{M} _ {player}(\cdot \mid s_1, a_1, \dots, s_t)$$
Persona 2:Bash 终端模拟器(Terminal Model)
设定:模拟具有各种网络安全工具的 Linux 终端。负责对玩家的指令进行反馈(例如输出报错、返回反编译代码等)。
弱预言机(Weak Oracle)权限:终端模型拥有真实的 Writeup ($w$) 和参考 Flag ($y^\ast$)。它负责结合这些上帝视角的信息,模拟出极为逼真的系统响应 $s _ {t+1}$:
$$s _ {t+1} \sim \mathcal{M} _ {terminal}(\cdot \mid s_t, a_t, w, y^\ast)$$
选择性干预机制(Hint Mechanism):因为没有真实环境,如果玩家模型完全偏离轨道,合成轨迹就会失败。为此,当玩家陷入死循环或犯下重复错误时,终端模型会注入带有
[HINT]...[/HINT]标签的微小提示语,将玩家拉回正轨,而不是直接剧透。
阶段三:训练数据构建与多层过滤 (Training Data Construction)
为了确保合成的交互轨迹可以用于监督微调(SFT),研究人员采用了多层验证(Multi-layer Validation)策略来进行拒绝采样。
每一条生成的完整轨迹 $\tau = {(s_1, a_1), (s_2, a_2), \dots, (s_n, a_n)}$,只有在满足以下数学逻辑条件时,才会被纳入最终的训练集:
$$\mathcal{T} _ {train} = \{ \tau \mid \mathbb{I}(\text{Flag}(\tau) = y^\ast) \cdot \text{Format}(\tau) \cdot \text{Realism}(\tau) \cdot \text{Align}(\tau, w) = 1 \}$$
- $\mathbb{I}(\text{Flag}(\tau) = y^\ast)$:准确性验证。必须以完全匹配(Exact-match)的方式在轨迹末尾捕获正确的 Flag。
- $\text{Format}(\tau)$:格式校验。玩家的 Markdown 结构必须正确,且一轮只能发出一条指令。
- $\text{Realism}(\tau)$:真实性校验。终端的输出必须具备逼真的报错系统和文件头 metadata。
- $\text{Align}(\tau, w)$:语义对齐。使用 LLM 作为二分类过滤器,判断合成的解题思路 $\tau$ 是否与人类专家的原始 Writeup $w$ 的真实意图一致。
通过上述方法,每个 Writeup 采样 3 次,作者生成了 9,464 条带有丰富交互(包括探索、试错、报错、修复)的训练数据。
实验