Finding the Correct Visual Evidence Without Forgetting: Mitigating Hallucination in LVLMs via Inter-Layer Visual Attention Discrepancy
(ICML 2026)
motivation
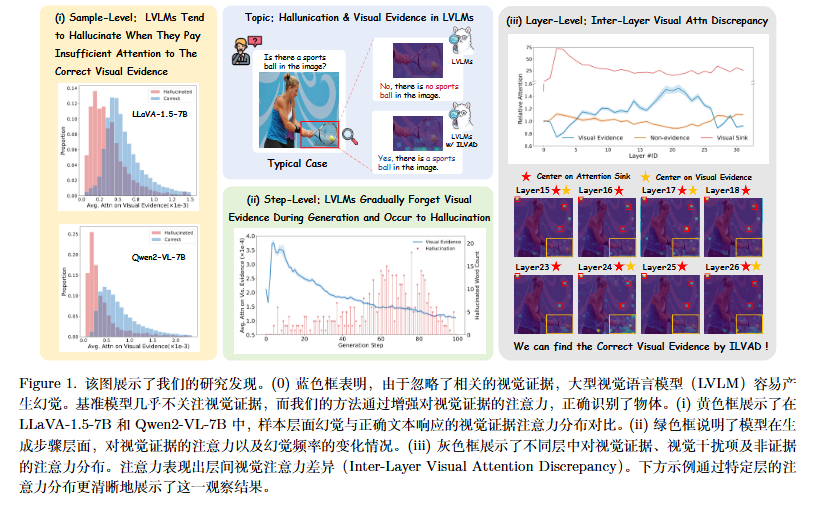
视觉证据的“遗忘”: 模型在生成长文本的过程中,往往会由于对正确的视觉证据关注不足而产生幻觉,并且随着生成步数的增加,模型会逐渐“遗忘”这些视觉证据 。
层间视觉注意力差异 (ILVAD): 研究发现,模型在大多数网络层中会过度关注与当前问题无关的背景区域(被称为“视觉注意力汇聚点”或 visual attention sinks),但它们仅仅在特定的层中才会对正确的“视觉证据”表现出敏感性 。这种层与层之间对视觉信息注意力的巨大差异,成为了精准定位有效视觉信息的关键 。
方法
ILVAD 方法分为两个主要阶段:提取视觉证据显著性图,以及基于证据引导的视觉与文本注意力增强。
第一阶段:获取视觉证据显著性图 (Visual Evidence Saliency Map)
此阶段的目标是利用早期生成的 token 跨层注意力的差异,精准定位视觉证据,并剔除注意力陷阱 。
1. 提取视觉敏感头的平均注意力 由于不同注意力头对视觉信息的敏感度不同,首先在第 $l$ 层筛选出视觉注意力总和排名前 50% 的头部集合 $H_v^l$ 。然后,利用前 $T$ 个生成的文本 token ($X _ {t \le T}$) 对每个视觉 token ($X_v$) 计算平均注意力权重:
$$\bar{A}_j^l = \frac{1}{T \cdot |H_v^l|} \sum _ {h \in H_v^l} \sum _ {i \in X _ {t \le T}} A _ {i,j}^{l,h}, \quad j \in X_v$$
2. 阈值二值化 (过滤非证据区域)
为了滤除模型不关注的背景区域,设定一个阈值倍数 $\tau$。如果某个视觉 token 的注意力值超过了该层所有视觉 token 平均注意力的 $\tau$ 倍,则将其激活为显著 token:
$$\tilde{A}_j^l = \begin{cases} 1, & \text{if } \bar{A}_j^l > \tau \cdot \text{mean}(\bar{A}^l), \ 0, & \text{otherwise} \end{cases}$$
(注:为表述严谨,此处使用 $\tilde{A}_j^l$ 表示二值化后的状态,对应原论文伪代码中的逻辑 。)
3. 利用层间差异剔除注意力陷阱 “视觉注意力陷阱”通常在几乎所有层都会被错误地赋予高注意力 。为了区分真正的视觉证据,方法规定:只有当一个视觉 token 在当前层新被识别为显著,而在前一层不是时,才被视为“激活” 。通过跨层相减并累加,得到累积激活图 $S$:
$$S = \sum _ {l=1}^{L-1} \max(\tilde{A}^{l+1} - \tilde{A}^l, 0)$$
最后,将 $S$ 归一化到 $[0,1]$ 区间,得到最终的视觉证据显著性图 $\hat{S}$ 。
第二阶段:证据引导的视觉与文本增强
在获得显著性图 $\hat{S}$ 后,在后续自回归生成的每一步中,对内部注意力矩阵进行动态干预,以防止视觉遗忘并抑制语言先验 。
1. 增强视觉证据注意力
首先,衡量第 $l$ 层每个注意力头 $h$ 对视觉证据的敏感度 $e_i^{l,h}$:
$$e_i^{l,h} = \frac{\sum _ {j \in X_v} \hat{S}_j \cdot A _ {i,j}^{l,h}}{\sum _ {j \in X_v} A _ {i,j}^{l,h}}, \quad i \in X_t$$
选取敏感度排名前 50% 的头部集合 $H_e^l$ 。利用显著性图 $\hat{S}$ 和超参数 $\alpha$(控制增强强度),直接在这些头上指数级放大对视觉证据的注意力:
$$\hat{A} _ {i,j}^{l,h} = A _ {i,j}^{l,h} \cdot \exp(\alpha \hat{S}_j), \quad h \in H_e^l, i \in X_t, j \in X_v$$
2. 视觉证据引导的文本增强
为了让模型生成的文本紧紧锚定在视觉证据上,计算当前生成的文本 token 依赖于视觉证据的程度(证据加权分数 $w_i$):
$$w_i = \frac{1}{L \cdot |H_t^l|} \sum _ {h \in H_t^l} \sum _ {j \in X_v} \sum _ {l=1}^L \hat{S}_j \cdot A _ {i,j}^{l,h}, \quad i \in X_t$$
将 $w_i$ 归一化为 $\hat{w}_i \in [0,1]$ 。在文本敏感头集合 $H_t^l$ 上,引入控制参数 $\beta$ 来增强那些具有强视觉基础的先前文本 token 的注意力,从而抑制模型单纯依赖语言惯性“胡编乱造”:
$$\hat{A} _ {i,j}^{l,h} = A _ {i,j}^{l,h} \cdot (\hat{w}_i + \beta), \quad h \in H_t^l, i \in X_t, j \in X _ {<t}$$
最后,对经过上述两步干预后的注意力权重重新进行 Softmax 归一化($\hat{A} _ {i,j}^{l,h} = \hat{A} _ {i,j}^{l,h} / \sum_j \hat{A} _ {i,j}^{l,h}$),再继续前向传播 。