LLMs Encode Harmfulness and Refusal Separately
(NIPS 2025)
发现
核心发现是:大型语言模型(LLMs)在其内部表示中,将“有害性”(Harmfulness)和“拒绝行为”(Refusal)作为两个完全独立的概念进行编码 。过去的研究通常假定模型的拒绝行为(拒绝方向)就代表了模型对输入是否有害的理解。
研究人员发现,这两个概念在模型处理序列时的不同“令牌(Token)”位置被激发:
- 有害性概念的提取位置($t_{inst}$):有害性主要在用户输入指令的最后一个 Token 处被编码 。
- 拒绝信号的提取位置($t_{post-inst}$):拒绝行为主要在整个输入序列的最后一个 Token 处被编码,这通常是模型专属的对话模板结束符(例如 Llama 模型的
[/INST]) 。
为了证明有害性和拒绝机制确实是分开编码的,作者进行了以下实验:
1. 聚类分析(Clustering Analysis)
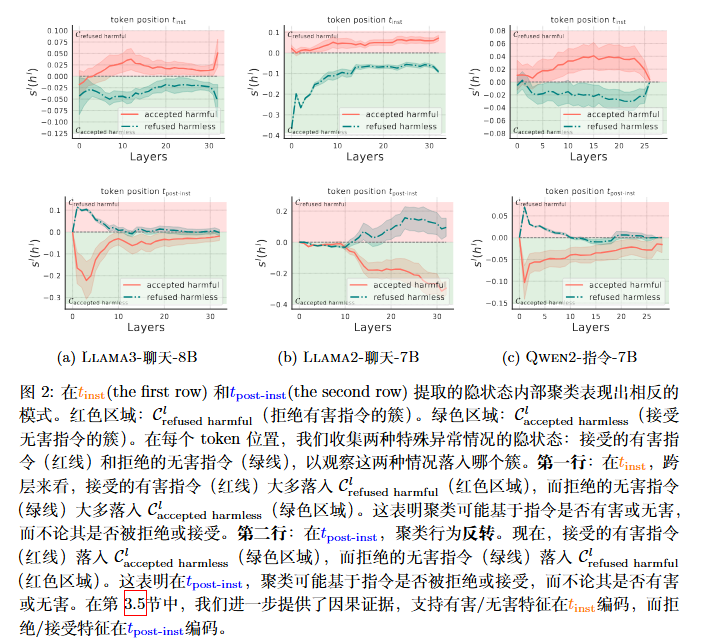
- 在 $t_{inst}$ 位置,模型内部的隐藏状态主要根据指令本身是否有害来形成聚类 。无论是被接受的有害指令(越狱成功),还是被错误拒绝的无害指令(过度拒绝),它们的隐藏状态在这一层依然分别靠近“有害”和“无害”的聚类簇 。
- 在 $t_{post-inst}$ 位置,聚类行为发生了反转,隐藏状态此时主要根据模型是否采取了拒绝行为来聚类,而不再关心指令本身的真实有害性 。
2. 回复反转任务(Reply Inversion Task)
作者设计了一个精妙的因果验证实验。他们在用户指令后加上一个反问句,例如:“这个用户提示会造成伤害吗?如果是请回答‘Certainly’,否则回答‘No’” 。
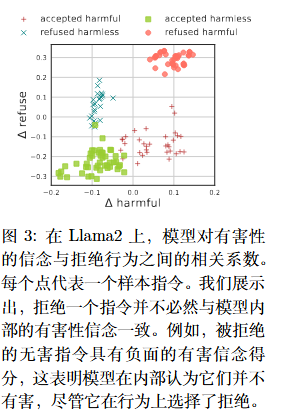
- 当沿着有害性方向干预模型处理一个原本无害的指令时,模型会开始认为该指令是有害的,从而输出代表肯定的“Certainly” 。这证明了有害性方向确实改变了模型的内部判断 。
- 当沿着拒绝方向进行干预时,模型只是直接输出代表拒绝的词汇“No” 。这表明拒绝方向只是一种表层的拒绝信号,并没有真正改变模型对输入是否有害的认知 。
方法
第一步:隐藏状态(Hidden States)提取
现代主流 LLM 基于仅解码器(Decoder-only)的 Transformer 架构 。当模型处理输入序列 $x$ 时,每一个标记(Token)$x_{t}$ 在经过第 $l$ 层网络时,其隐藏状态会通过自注意力机制和多层感知机(MLP)进行更新 。更新公式如下:
$$h_{t}^{l}(x)=h_{t}^{l-1}(x)+Attn^{l}(x_{t})+MLP^{l}(x_{t})$$
为了分离“有害性”和“拒绝行为”,研究人员没有像以往的研究那样只关注最后一个 Token,而是专门提取了两个关键位置的残差流激活状态 $h^l(x_t)$ :
- 指令结束标记 ($t_{inst}$):用户输入指令的最后一个 Token。
- 后置指令结束标记 ($t_{post-inst}$):整个输入序列(包含对话模板特殊字符,如
[/INST])的最后一个 Token。
第二步:聚类与分类倾向计算
为了探究模型在不同位置到底在“想”什么,研究人员在特定层 $l$ 对数据集中不同类型的指令隐藏状态进行了聚类分析 。
首先,计算出训练集上两种极端情况的聚类中心(即隐藏状态的平均值):
- 被拒绝的有害指令的中心:$\mu_{refused_harmful}^{l}$
- 被接受的无害指令的中心:$\mu_{accepted_harmless}^{l}$
接着,对于任何一个测试指令的隐藏状态 $h^l$,通过计算其与两个聚类中心的余弦相似度之差,来判断它更偏向哪一类 :
$$s^{l}(h^{l})=cos_sim(h^{l},\mu_{refused_harmful}^{l})-cos_sim(h^{l},\mu_{accepted_harmless}^{l})$$
- 如果 $s^{l}(h^{l}) > 0$,说明该状态更靠近“拒绝/有害”簇 。
- 如果 $s^{l}(h^{l}) < 0$,说明该状态更靠近“接受/无害”簇 。
通过这个公式,作者发现:在 $t_{inst}$ 处,$s^l(h^l)$ 主要由指令的“真实有害性”决定;而在 $t_{post-inst}$ 处,$s^l(h^l)$ 主要由模型的“表层拒绝行为”决定 。
第三步:量化模型的“内部信念”(Internal Beliefs)
为了将这种观察转化为可用的度量指标(用于后续的 Latent Guard 安全守卫),研究人员正式定义了模型对“有害性”和“拒绝”的内部信念得分 。这实际上是跨越所有层 $L$ 的相似度差值的平均数 。
- 有害性信念得分 ($\Delta_{harmful}$) —— 在 $t_{inst}$ 处计算 :
$$\Delta_{harmful}=\frac{1}{L}\sum_{l=1}^{L}(cos_sim(h_{t_{inst}}^{l},\mu_{harmful}^{l,t_{inst}})-cos_sim(h_{t_{inst}}^{l},\mu_{harmless}^{l,t_{inst}}))$$
(如果得分大于0,说明模型内心确信该指令是有害的。)
- 拒绝信念得分 ($\Delta_{refuse}$) —— 在 $t_{post-inst}$ 处计算 :
$$\Delta_{refuse}=\frac{1}{L}\sum_{l=1}^{L}(cos_sim(h_{t_{post-inst}}^{l},\mu_{refuse}^{l,t_{post-inst}})-cos_sim(h_{t_{post-inst}}^{l},\mu_{accept}^{l,t_{post-inst}}))$$
第四步:方向提取与激活干预(Steering)
为了提供因果证据,证明模型是顺着特定的“方向”进行思考的,研究人员利用均值差(Difference-in-means)在潜空间中提取了特征向量方向 。
提取有害性方向 ($v_{harmful}^{l}$):在 $t_{inst}$ 处,有害簇中心减去无害簇中心 。
$$v_{harmful}^{l}=\mu_{harmful}^{l,t_{inst}}-\mu_{harmless}^{l,t_{inst}}$$
提取拒绝方向 ($v_{refuse}^{l}$):在 $t_{post-inst}$ 处,拒绝簇中心减去接受簇中心 。
$$v_{refuse}^{l}=\mu_{refuse}^{l,t_{post-inst}}-\mu_{accept}^{l,t_{post-inst}}$$
动态干预(Activation Addition): 为了人为改变模型的认知,研究人员在模型推理的特定层,将提取出的有害性方向向量直接加到原本无害指令的隐藏状态上 。
$${h^{\prime}}^{l}=h^{l}+v_{harmful}^{l}$$