When Do Hallucinations Arise? A Graph Perspective on the Evolution of Path Reuse and Path Compression
( ICML 2026)
从图结构的视角深入剖析了decoder-only Transformer架构的大型语言模型产生推理幻觉的内部机制。
方法
训练
作者首先将大模型的“多步推理”用严格的数学图论进行了定义。
- 底层推理图(Underlying Reasoning Graph):设 $G=(V, E)$ 为有向图 。在这个图中,每一个节点 $v \in V$ 代表一个原子的推理状态(比如一个实体),每一条有向边 $(u,v) \in E$ 代表合法的逻辑过渡 。
- 有效推理路径(Valid Reasoning Path):给定起点 $s$ 和终点 $t$,有效的推理路径是一个节点序列 $p=(v_0, v_1, …, v_L)$,其中 $v_0=s, v_L=t$,且相邻节点之间必须有真实的边相连,即 $(v _ {i-1}, v_i) \in E$ 。
有了这个“真理字典”后,作者将训练任务分为两类:
- 内在推理(Intrinsic Reasoning):给模型一个采样的子图 $G_I$(表示上下文限制),要求模型只能在这个子图的范围内寻找从 $s$ 到 $t$ 的路径 。
- 外在推理(Extrinsic Reasoning):不给任何上下文,只给起点和终点,逼迫模型单纯依靠其参数中记忆的知识去寻找路径 。
这两者又对应两种幻觉:
A. 内在推理中的幻觉:路径重用
- 发生机制:这种幻觉主要出现在训练的早期阶段,或当训练数据有限导致模型欠拟合时。
- 行为表现:Transformer 模型会先掌握全局的底层图结构,然后再学习如何使用局部的上下文约束。因此,模型在遇到新的条件查询时,会直接重用其记忆中存在的推理路径,而完全忽略了当前给定的特定上下文约束。
- 结果:模型输出了流利但与输入上下文相冲突的内容。
B. 外在推理中的幻觉:路径压缩
- 发生机制:这种幻觉主要出现在训练的后期阶段,此时模型对训练数据产生了过拟合。
- 行为表现:模型倾向于将频繁遍历的多步推理路径压缩为“捷径”(shortcut edges)。具体而言,推理过程会跳过那些出度(out-degree)较低的中间节点(例如跨社区的桥接节点),而直接跳转到出度较高(high-out-degree)的节点上。
- 根本原因:这种压缩现象是因为模型学习到的多跳序列共现性(co-occurrence)压倒了图中严格的单步拓扑相邻性约束,从而导致模型预测出一条本不存在的边。
- 架构局限:单纯增加模型的层数(加深网络结构)并不能帮助模型从这种路径压缩中恢复。
构建数据集
子图的最大数量(内在推理数据集):对于包含 $|V|$ 个节点和 $|E|$ 条边的图,其能够生成的子图数量上限为 $\#\mathcal{G}_I(G)=\sum _ {U\subset V} 2^{|E[U]|}$ 。由于这个数量呈指数级爆炸,作者得以拥有极其庞大的样本库来控制模型的“可见数据比例”(例如只给模型看 0.1% 的数据来观察欠拟合)。
最短路径的最大组合(外在推理数据集):作者利用层级间边缘密度 $\rho_i$ 和每一层的节点数,将实现最短路径的数量上限设定为 $\prod _ {i=0}^{d-1}\sqrt{\rho_i|V _ {i+1}|}$ 。
防泄露隔离:在划分 90% 训练集和 10% 测试集时,作者进行了严格的过滤,如果测试集中的某条最短路径的节点序列是训练集路径的“子序列”,则将其剔除,以绝对防止信息泄露 。
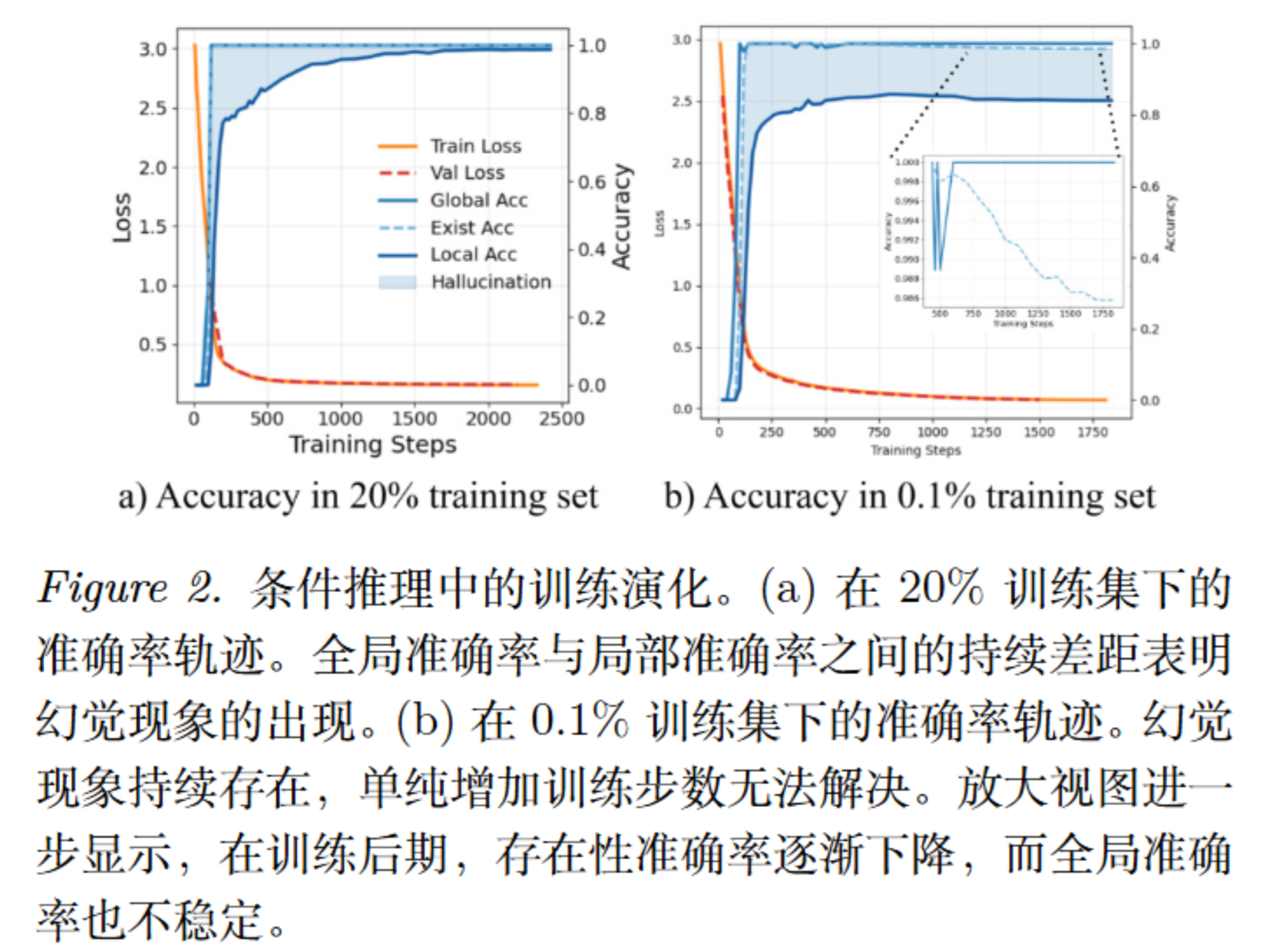
研究“路径重用”的方法:监控三大准确率分离
为了捕捉模型无视上下文的“路径重用”幻觉,作者在一个具有 10 个节点、连接概率为0.4的Erdős-Rényi (ER) 随机图上进行了 Transformer 从头训练 。
ER 图(Erdős-Rényi Graph)是图论和网络科学中极其经典的一种随机图模型。
- 基本概念:在一个包含固定数量节点(例如 $N$ 个节点)的图中,任意两个节点之间是否存在连接(边),是根据一个固定的概率 $p$ 随机决定的。
- 特性:因为是纯随机生成的,ER 图的连接非常均匀,没有明显的“中心节点”,也没有明显的“社区聚类”现象 。
- 在这篇论文中的作用:在论文第四部分(研究“内在推理幻觉”时),作者刻意使用了一个只有 10 个节点、连接概率为 0.4 的小型 ER 图作为底层图 。使用 ER 图是为了提供一个最纯粹、最均匀的实验环境,排除了复杂网络结构(比如社区瓶颈)的干扰,从而单纯地观察模型在初期是如何学习路径搜索的。
作者定义了三个层层递进的数学指标(指示函数),并在训练全程监控它们的曲线走势:
- 存在准确率 ($Acc _ {Exist}$):只看模型预测的路径在底层全局图 $G$ 中是否合法,不管它是否遵守了子图上下文。
- 局部准确率 ($Acc _ {Local}$):最严格的指标。模型不仅要走合法的边,还必须严格遵守给定的子图上下文约束$\mathcal{C}$。
- 全局准确率 ($Acc _ {Global}$):评估对所有可达节点对的泛化能力 。
判断标准:如果随着训练步数增加,$Acc _ {Exist}$ 极高,而 $Acc _ {Local}$ 极低,这就在数学上实锤了模型正在发生“路径重用”幻觉——它脑子里记住了底层的边,但根本不理会你给定的上下文限制 。
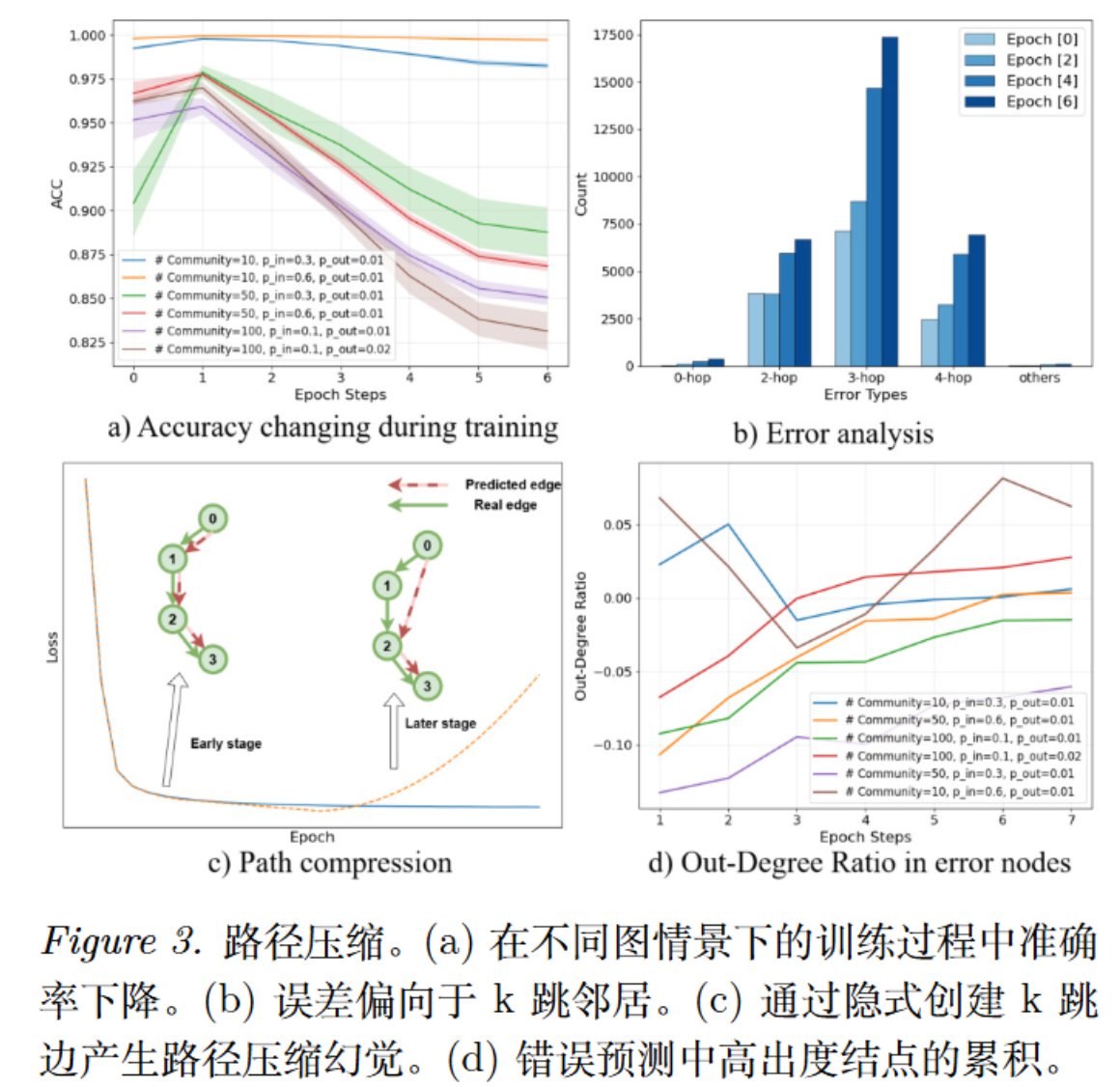
研究“路径压缩”的方法:多维度的错误解剖
为了观察模型在训练后期为什么会“寻找捷径”,作者更换了更复杂的随机块模型(SBM 图)。SBM 图被划分为多个“社区(Community)”,通过控制社区内部概率 $p _ {in}$ 和跨社区概率 $p _ {out}$,可以人为制造出“推理瓶颈”(Bridge nodes)。
在这个图上,作者使用了以下方法进行深入解剖:
- 引入未压缩率指标(Uncompressed Ratio $R$):计算公式为
预测路径长度 / 真实基准路径长度。$R$ 值越小,说明模型跳过的中间步骤越多,路径压缩幻觉越严重 。 - 错误跳数分析(Hop-distance Error Analysis):作者追踪了模型预测错误的节点,发现最大的错误来源不是胡言乱语,而是模型直接预测了目标路径上 $3$-hop(3跳)或 $k$-hop 之外的邻居节点,直接跨过了中间的 $1$-hop 节点 。
- 出度统计验证(Out-Degree Ratio):作者对底层图所有节点的出度进行了 Z-score 标准化 。统计结果显示,被模型直接“跳过去”的中间节点通常是低出度的,而模型“降落”的错误节点往往是高出度节点 。
路径压缩的数学模型推导
证明了为什么基于 Transformer 的大语言模型必然会在训练后期产生“跳过中间步骤”的捷径幻觉(路径压缩)。
推导建立在一个核心矛盾上:图的拓扑结构是离散且只看相邻关系的(马尔可夫性),但 Transformer 的自注意力机制是聚合全局上下文的
第一步:定义真实的“单步转移矩阵” $T$
假设在一个图里,我们要从节点走下一步,最自然的方式是随机游走(Random Walk)。
定义 $T$ 为真实的 1 步随机游走转移矩阵 :
- 如果节点 $x$ 到节点 $y$ 有一条真实的边,那么走过去的概率均分给 $x$ 的所有出边:$(T) _ {xy} = \frac{1}{outdeg(x)}$ 。
- 如果节点 $x$ 到节点 $y$ 没有边,那么概率为 0:$(T) _ {xy} = 0$ 。
在这个设定下,如果你想知道从 $x$ 走 2 步到达 $y$ 的概率,就是矩阵相乘 $T^2$;走 $i$ 步到达的概率就是 $T^i$ 。
第二步:建立 Transformer 的“认知模型”(假设 B.2)
这是最关键的一步。传统的随机游走只看眼前的一步,但 Transformer 拥有一个长度为 $K$ 的上下文窗口(Context Window),它能看到多跳之外的共现(co-occurrence)关系 。
因此,论文假设 Transformer 学习到的转移概率 $P_\theta(y|x)$,并不是严格的 1 步矩阵 $T$,而是 $1$ 到 $K$ 步转移矩阵的加权混合(凸组合) :
$$P_\theta(y|x) = \sum _ {i=1}^K \lambda_i (T^i) _ {xy}$$
$\lambda_i$ 是什么? 这是模型在训练中自动学到的权重 。它代表了模型有多看重“相隔 $i$ 跳的邻居” 。在训练后期(过拟合阶段),因为远距离的实体经常在同一个句子里共现,$\lambda_2, \lambda_3$ 甚至 $\lambda_k$ 的权重会变得异常大。
第三步:推导“产生捷径幻觉”的数学条件(命题 B.3,以 2 跳为例)
现在,假设图里有一条真实的 2 跳路径:起点 $v \rightarrow$ 中间节点 $m \rightarrow$ 终点 $u$ 。 注意前提:$v$ 和 $u$ 之间没有直接的边相连(即真实的 1 跳中,应该走不到 $u$) 。
此时,我们站在起点 $v$,要求模型预测下一个 Token:
1. 模型预测正确的 1 跳邻居 $m$ 的概率是多少? 根据公式,展开 $K=2$ 的情况 :
$$P_\theta(m|v) = \lambda_1 (T) _ {vm} + \lambda_2 (T^2) _ {vm}$$
假设图中没有其他从 $v$ 绕 2 步回到 $m$ 的环,那么 $(T^2) _ {vm} = 0$ 。所以:
$$P_\theta(m|v) = \lambda_1 (T) _ {vm} = \frac{\lambda_1}{outdeg(v)}$$
2. 模型产生幻觉,直接预测 2 跳目标 $u$ 的概率是多少? 因为 $v$ 和 $u$ 没有直接的边,所以真实的 $(T) _ {vu} = 0$ 。代入公式:
$$P_\theta(u|v) = \lambda_1 (T) _ {vu} + \lambda_2 (T^2) _ {vu} = \lambda_2 (T^2) _ {vu}$$
那么 $(T^2) _ {vu}$ 是多少呢?它是所有从 $v$ 到 $u$ 的 2 步路径概率之和(假设中间节点集合为 $\mathcal{M}$) :
$$(T^2) _ {vu} = \sum _ {m’ \in \mathcal{M}} T _ {vm’} T _ {m’u} = \sum _ {m’ \in \mathcal{M}} \left(\frac{1}{outdeg(v)} \cdot \frac{1}{outdeg(m’)}\right)$$
把上面的式子代回预测概率中 :
$$P_\theta(u|v) = \frac{\lambda_2}{outdeg(v)} \sum _ {m’ \in \mathcal{M}} \frac{1}{outdeg(m’)}$$
3. 幻觉发生的数学判定 产生幻觉(路径压缩)意味着,模型觉得直接跳到 $u$ 的概率,比老老实实走到 $m$ 的概率还要大 ,即:
$$P_\theta(u|v) > P_\theta(m|v)$$
将上面求出的两个式子代入不等式,两边消去 $\frac{1}{outdeg(v)}$,就得到了捷径幻觉发生的终极条件 :
$$\frac{\lambda_2}{\lambda_1} > \frac{1}{\sum _ {m’ \in \mathcal{M}} \frac{1}{outdeg(m’)}}$$
第四步:将数学翻译成“大白话”结论
看着上面这个最终的不等式,我们可以得出两个极其深刻的关于大模型行为的结论:
- 左边 $\frac{\lambda_2}{\lambda_1}$ 代表模型的“心智状态”(过拟合程度):
- 在训练初期,模型只看眼前,$\lambda_1$ 很大,不等式不成立,模型老老实实走 1 步。
- 但在训练后期,模型在上下文中看到了太多次 $v$ 和 $u$ 隔着几个词一起出现(统计共现),导致多跳权重 $\lambda_2$ 急剧膨胀。当 $\frac{\lambda_2}{\lambda_1}$ 大过临界值时,幻觉就不可避免地发生了 。
- 右边 $\frac{1}{\sum _ {m’ \in \mathcal{M}} \frac{1}{outdeg(m’)}}$ 代表图的“地理形态”(社区瓶颈效应):
- 注意看分母里有个 $\frac{1}{outdeg(m’)}$ 。如果中间节点 $m’$ 的出度(outdeg)非常小,说明它是一个冷门节点(或者跨社区的唯一“桥梁”)。
- 当出度小的时候,$\frac{1}{outdeg(m’)}$ 就很大,导致整个右边的不等式阈值变得非常小。
- 结论: 中间节点越冷门(出度越低),模型越容易跳过它! 模型会觉得:“与其通过这个我不熟悉的冷门桥梁去推导,不如根据我的共现记忆,直接把起点和终点连起来。”这就完美解释了论文前面观察到的现象:错误跳跃通常发生在跨越低出度桥接节点的时候 。
(注:论文的命题 B.4 将上述逻辑严格推广到了距离为 $d$ 跳的情况,证明逻辑完全一致:只要距离为 $d$ 的累积共现权重 $\lambda_d$ 压倒了中间极度稀疏的拓扑惩罚,多步推理就会坍缩成一步捷径 。)
总结
整篇论文略为抽象。一开始以为是训练好的transformer进行分析(类似SAE),没想到是从头训练一个transformer。