HALP: Detecting Hallucinations in Vision-Language Models without Generating a Single Token
(arxiv 2026)
涉及模型:
- Gemma-3
- LLaVA-Next
- Llama-3.2-Vision
- Phi-4-VL
- Molmo
- Qwen2.5-VL
- SmolVLM
- FastVLM
提取的嵌入:
视觉特征 (VF, Visual Features):在多模态投影层 $\mathcal{M}$ 之前,视觉编码器输出的全局平均池化向量:$\overline{u}=\frac{1}{M}\sum_{i=1}^{M}u_{i}$ 。这代表了未与文本融合的纯视觉感知信息 。
视觉 Token 表示 (VT, Vision Token Representations):来自解码器第 $l$ 层,视觉 token 序列 $V$ 的最后一个位置的隐藏状态 。这捕获了视觉信息在多模态文本解码器内部是如何被处理的 。
查询 Token 表示 (QT, Query Token Representations):来自解码器第 $l$ 层,查询 token 序列(即拼接序列 $(V,Q)$ 的最后)的最终位置的隐藏状态 。这编码了直接用于文本生成前的完全上下文化的多模态信息 。
对于 VT 和 QT,作者策略性地选择了五个深度层进行测试:$l\in{1,\lfloor L/4\rfloor,\lfloor L/2\rfloor,\lfloor3L/4\rfloor,L}$ 。
对于特定层的每种表示,独立训练一个轻量级的探测器。该探测器是一个 3 层的多层感知机 (MLP),隐藏层维度为 [512, 256, 128],使用 ReLU 激活函数 。
探测器输出一个介于 0 到 1 之间的风险分数 $s^{j}\in[0,1]$,分数越高,代表模型越有可能对该输入产生幻觉 。
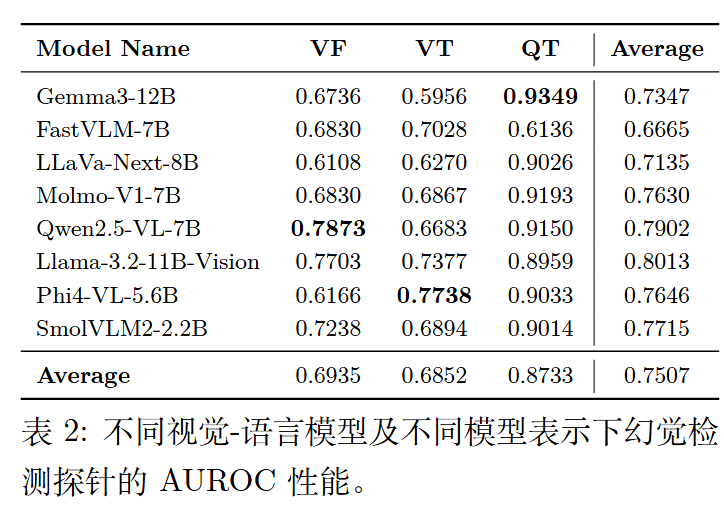
检测效果
幻觉策略
早期拒绝/延迟 (Early refusal):当 HALP 预测到极高的幻觉风险分数时,系统可以直接回复“我不确定”或要求用户提供更清晰的输入,从而拦截幻觉 。
选择性路由 (Selective routing):低风险的请求由快速的基础模型处理;高风险的请求则被路由到计算成本更高、能力更强的模型进行处理,以优化整体成本和安全性 。