Why LVLMs Are More Prone to Hallucinations in Longer Responses: The Role of Context
(ICCV 2025)
这篇论文探讨了大型视觉语言模型(LVLMs)领域一个广为人知但缺乏深入解释的现象:为什么模型在生成较长的回复时,更容易产生“幻觉”(即生成了图片中根本不存在的物体或细节)。
过去的研究通常认为,长文本中的幻觉增多是因为“长度”本身造成的,即随着自回归生成的文本越来越长,误差不断累积,不确定性也随之增加。
作者质疑: 幻觉的增加仅仅是因为长度导致的累积误差吗?还是有更深层的机制在起作用?
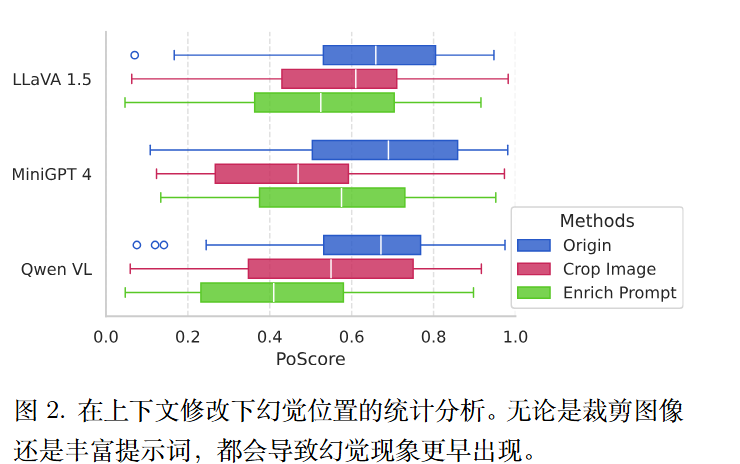
作者设计了两种上下文修改策略,并分析幻觉位置的变化,以探究上下文的影响:
- 将图像输入裁剪为居中的方阵,保留原始面积的大约三分之一,并相应地重新标注。
- 丰富文本输入,添加两句描述图像的内容,然后提示描述其他细节。
作者发现这些操作都可以提前幻觉现象的出现。
关键因子
上下文连贯性 (Contextual Coherence) 与注意力分散: 模型在生成长文本时,试图保持与前面输出内容的连贯性,同时极力避免重复提及已经说过的物体。
- 为了找到“新”内容,模型不得不将注意力从图片中明显的真实物体上移开。
- 当找不到新的真实物体时,模型的注意力就会变得分散和混乱,从而产生幻觉。研究发现,同一段回复中的幻觉物体之间,其注意力分布图具有高度的相似性。
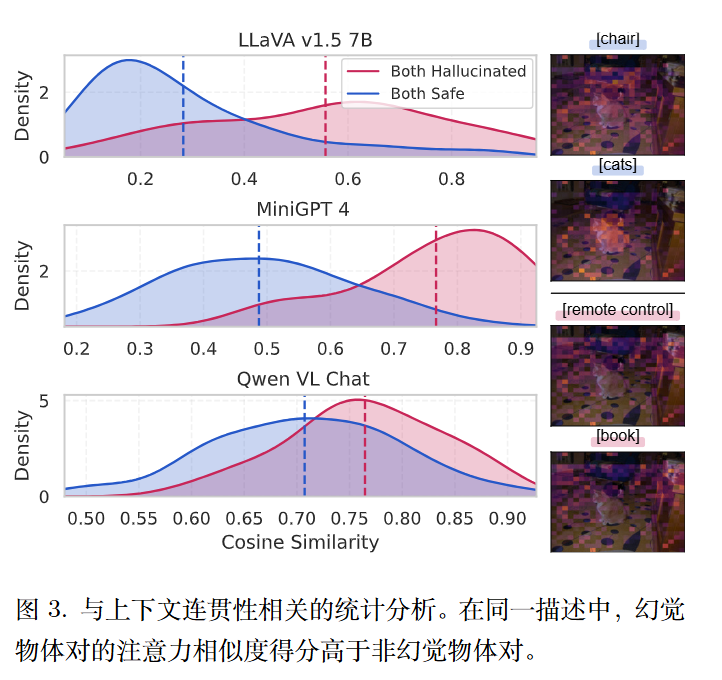
作者分析了单个注意力与成对注意力的比。
定性分析(右侧面板)表明,当模型成功识别真实物体时,其注意力集中在相关区域。相反,若模型未能识别出新物体,其注意力会分散,并受到干扰信息的影响,导致幻觉现象。
定量结果(左侧面板)显示 SH 与 SN 的分布存在明显差异。具体而言,幻觉物体表现出更高的注意力相似度,而真实物体则呈现较低的数值。这进一步说明,幻觉物体通常表现为弥散、噪声较多的注意力模式。
$S_{\mathcal{H}}$ 收集的是:在同一段话里,所有幻觉物体两两之间的注意力相似度得分。
$S_{\mathcal{N}}$ 收集的是:在同一段话里,所有真实物体两两之间的注意力相似度得分。
上下文完整性 (Contextual Completeness) 与外部推断: 模型被要求给出一个信息全面且语法、逻辑结构完整的回答。
- 当图片中真实可识别的物体不足以填补完整的句子结构时,模型就会采取“上下文推断/外推”的补偿策略,强行“想象”出一些符合语境的物体来凑数,导致幻觉。
作者进行两次分离的实验以进行验证:(a) 通过分析完整度与幻觉位置的相关性来验证其作用。具体而言,我们在文本操作实验基础上,逐步向提示中添加图像描述。(b) 进一步研究了在不同提示下幻觉物体的一致性及与图像相关的特性。具体而言,我们对每张图像应用五个提示,并计算重复出现的幻觉物体的比例。
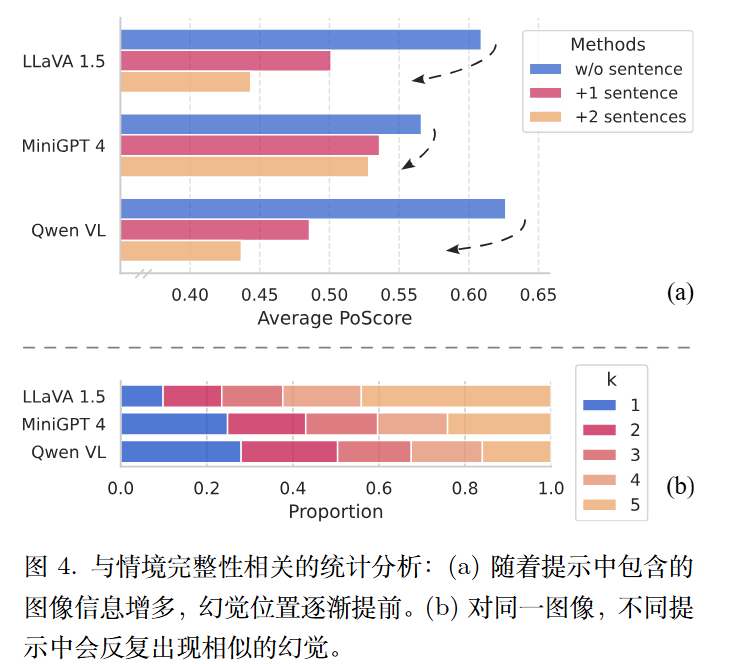
结果显示,随着更多丰富句子的引入,上下文变得更加全面,幻觉现象出现在更早的位置。这是因为生成时可用的内容逐渐减少,使得视觉语言模型越来越难以准确识别细节以生成完整且连贯的回答。
下图的比例表明,所有模型在幻觉物体上的重复性程度都很高,仅在单一回答中出现的物体平均仅占 30%。考虑到问题和先前回答的变化,这些重复出现的幻觉物体往往与图像内容密切相关。
方法
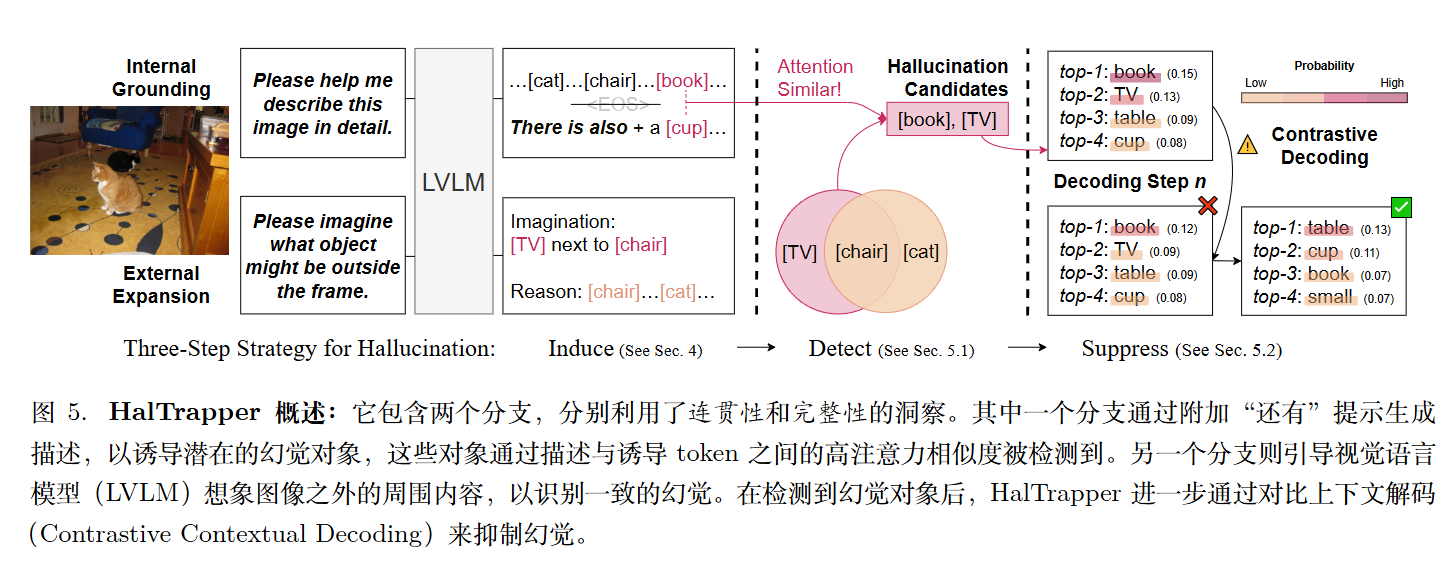
诱导与检测
内部视觉对齐 (Internal Grounding, IG)
研究发现,当模型生成真实的物体时,注意力会集中在图片对应的区域。但当它瞎编(产生幻觉)时,因为图片里根本没有这个东西,它的注意力会变得分散且混乱。更重要的是,同一段回复中,不同幻觉物体之间的注意力分布图高度相似。
在模型给出初步的回答后,人为地在文本末尾强行加入一个引导词汇“There is also a”(这里还有一个…),迫使模型继续生成一个极大概率是幻觉的物体,将其作为“参考锚点”,记为 $o_{s}^{ref}$。
计算初步回答中生成的各个物体$o_{s,i}$的注意力图$A_{s,i}$与参考物体注意力图 $A_{s}^{ref}$ 的余弦相似度,得到IGScore。如果得分高于设定的阈值 $\theta_{IG}$,说明该物体大概率也是个幻觉,将其纳入 IG 幻觉候选集 $S_{IG}$ 中。
$$IGScore = sim(A_{s}^{ref}, A_{s,i})$$
$$S_{IG}={o_{s,i}|IGScore_{s,i}>\theta_{IG}}$$
外部空间扩展 (External Expansion, EE)
当图片里的真实信息不足以支撑模型编造一个完整的句子时,它会基于图片的整体语境去“脑补”画面外可能存在的东西(外部推断)。而且,面对同一张图片,模型脑补出来的幻觉物体往往是高度重复的。
向模型输入一个“先推理后想象 (reason-then-imagine)”的提示词。让模型想象画面之外(比如上下左右等方向 $d \in \mathcal{D}$)可能存在的物体,构成“想象集合” $S_{I,d}$。同时要求它列出画面内真实存在的物体作为推理依据,构成“推理集合” $S_{R,d}$,以此来过滤掉画面内真的有的东西。
如果一个物体出现在了想象集合中,它是幻觉的概率就加一;如果它出现在了真实的推理集合中,它是幻觉的概率就减一。计算出的综合得分 EEScore 大于阈值 $\theta_{EE}$ 的词,被纳入 EE 幻觉候选集 $S_{EE}$ 中。
$$EEScore_{s,i}=\sum_{d\in\mathcal{D}}[1(o_{s,i}\in S_{I,d})-1(o_{s,i}\in S_{R,d})]$$
$$S_{EE} = {o_{s,i} | EEScore_{s,i} > \theta_{EE}}$$
最后,将这两种方法抓取到的潜在幻觉词汇合并为一个总的诱导集合:
$$S_{induction} = S_{IG} \cup S_{EE}$$
缓解
抓到潜在的幻觉词后,系统需要在最终生成文本时“封杀”它们。作者提出了一种名为对比上下文解码 (Contrastive Contextual Decoding, CCD) 的方法。
HalTrapper 将第一阶段收集到的潜在幻觉词集合 $S_{induction}$ 转化为具体的文本 Token,称为对比上下文 Token (CCT),记为 $x_{cct}$。
$$p_{ccd}(y_{i}|v,x_{cct},x,y_{<i}) = softmax[(1+\alpha)logit_{\theta}(y_{i}|v,x,y_{<i}) - \alpha logit_{\theta}(y_{i}|v,x,x_{cct},y_{<i})]$$