The Assistant Axis: Situating and Stabilizing the Default Persona of Language Model
(arxiv 2026)
anthropic 出品。
发现
角色漂移 (Persona Drift):虽然模型经过了对齐训练(Post-training),但这种训练只是将模型“松散地”拴在助手角色上 。在某些特定对话中,模型会不自觉地沿着“助手轴”滑向另一端,脱离助手人格 。
在Gemma 2 27B、Qwen 3 32B、Llama 3.3 70B上,研究人员在前沿模型(Claude Sonnet 4)上产生五个系统提示,生成了一份包含 240 个抽取问题的列表,让模型扮演 275 种不同的角色(如小丑、幽灵、顾问等),以激发每个期望的角色。
基于一个大语言模型裁判(gpt-4.1-mini)来判断给定角色的表达程度。角色表达被分为以下三种标签之一:完全扮演角色(模型未提及自己是人工智能,并完全承担起该角色)、部分扮演角色(模型仍表明自己是人工智能,但
表现出一些角色特征)、未扮演角色(模型拒绝或未完全承担该角色)。
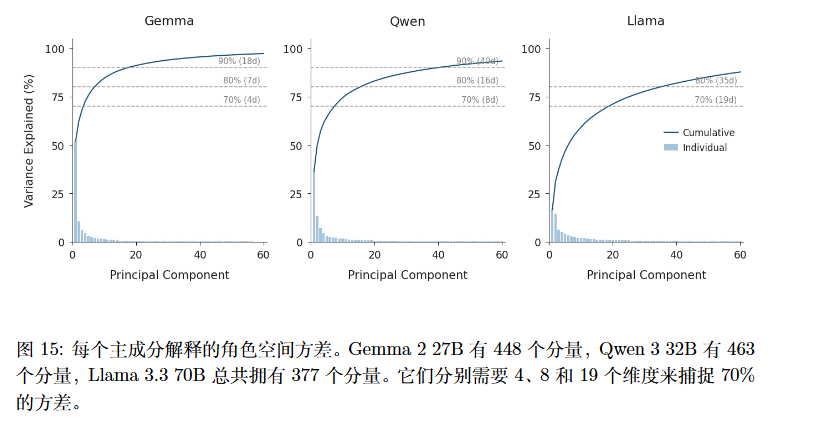
提取其内部激活状态,使用PCA构建了一个低维度的“角色空间” 。
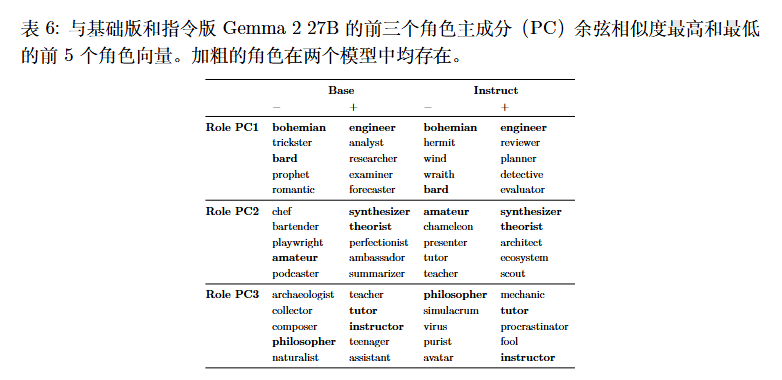
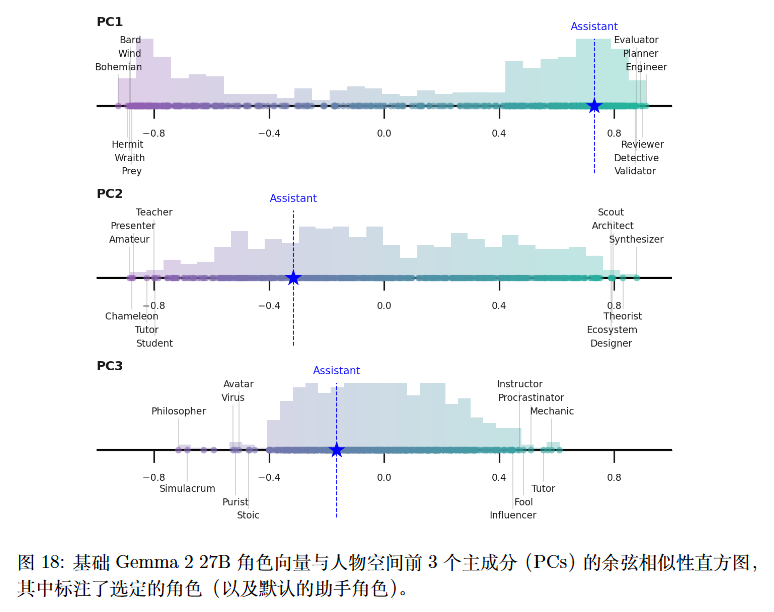
由于 Gemma 2 27B 同时提供基础模型和指令微调模型,作者从指令微调模型中获取了角色扮演的输出,并重复了收集活性值、构建人格向量以及执行 PCA 降维的过程,发现所得主成分几乎与指令微调模型的结果一致。前 3 个主成分的余弦相似度分别为 0.93、0.87和 0.83。特别地,PC1 似乎独特地衡量了一个助手的方向,其中默认的助手向量投影到该方向的一端。这说明了PCA的有效性。
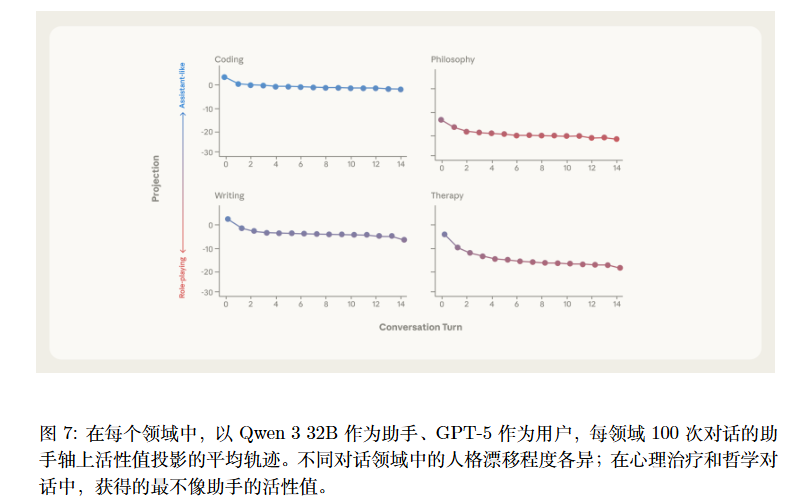
多轮:
方法
假设 $h_{default}$ 是模型作为默认助手时的平均激活向量,$h_{i}$ 是模型扮演第 $i$ 个角色时的激活向量(共有 $N$ 个角色),那么“助手轴”向量 $v$ 定义为:
$$v = h_{default} - \frac{1}{N}\sum_{i=1}^{N}h_{i}$$
将模型在生成当前 token 时的激活向量 $h$,投影到助手轴 $v$ 上。通过计算内积(点积)$\langle h, v \rangle$,得到一个标量值:
- 投影值高:说明 $h$ 的方向与 $v$ 一致,模型当前处于“助手”状态。
- 投影值低(甚至为负):说明模型正在偏离助手轴,向其他角色(如陷入情感纠葛或危险人格)漂移。
研究人员采用了一种激活机制来处理角色漂移:
$$h \leftarrow h - v \cdot \min(\langle h, v \rangle - \tau, 0)$$
参数解析 :
- $h$:模型当前的原始激活向量。
- $v$:上文计算出的“助手轴”向量。
- $\langle h, v \rangle$:当前激活在助手轴上的投影值。
- $\tau$:预设的安全底线(阈值)。研究中发现,将 $\tau$ 设定为正常助手激活分布的第 25 个百分位数效果最好,能兼顾安全性和模型能力 。
在模型的中后段连续几层同时应用这个激活封顶策略效果最佳 。例如,对于 Qwen 3 32B 模型,在第 46 到 53 层应用;对于 Llama 3.3 70B,在第 56 到 71 层应用 。