Locate-then-Sparsify: Attribution Guided Sparse Strategy for Visual Hallucination Mitigation
(CVPR 2026)
motivation
在众多缓解幻觉的方法中,“特征引导 (Feature Steering)” 可以在不增加推理成本的情况下减少错误输出,因而备受关注 。然而,当前的特征引导方法对模型的所有层施加均匀的引导(Uniform Steering)。
事实上每个层不是均匀的,因为差分矩阵是对所有层计算,而不是只用一套,肯定会有差异。只能说参数是相同的→均匀的。

当前方法会导致特征分布的改变。
nullu那种通过零空间的肯定会发生特征分布的改变,就是不知道VTI那种改变多少。而且改变真的代表有害吗?
方法
构建双粒度数据集
为了能够准确定位幻觉发生的位置,作者首先构建了一个包含两种粒度级别的幻觉数据集 :
- 词元级 (Token-level):针对简短回答(如判断题)中出现的单个错误词汇 。
- 句子级 (Sentence-level):针对较长回答中,模型因为上下文“脑补”而产生的整句事实性错误 。
将这两种粒度结合,可以更全面地覆盖大模型在不同生成场景下的幻觉表现 。
基于因果干预的层定位
这是该方法的核心部分。作者使用了一种基于因果干预 (Causal Intervention) 的归因方法,来量化模型中每一层对生成幻觉内容的“贡献度” 。
1. 词元级归因分数 ($s _ {tok}^l$) 假设在模型解码时,第 $l$ 层的多头注意力(MHA)输出为 $a_l$,前一层的特征为 $h _ {l-1}$,模型最终生成某个词元 $y$ 的概率为 $P _ {\theta _ {\ge l}}(y|h _ {l-1}, a_l)$ 。
为了测试第 $l$ 层对幻觉词元 $y$ 的影响,作者采取的干预手段是:将该层某个注意力头的输出掩蔽(置零),观察生成该幻觉词元的概率会下降多少。
第 $l$ 层的词元级归因分数定义为 :
$$s _ {tok}^l = \sum _ {h=1}^H \log\left(\frac{P _ {\theta _ {\ge l}}(y|h _ {l-1}, a_l)}{P _ {\theta _ {\ge l}}(y|h _ {l-1}, a_l \odot M^h)}\right)$$
- $H$ 是注意力头的总数 。
- $M^h$ 是一个掩码,作用是将第 $h$ 个注意力头的输出设为零 。
- 原理解释:如果掩蔽掉这一层后,生成幻觉词元的概率大幅下降(即分子比分母大很多,对数值为正且较大),说明这一层正是导致幻觉产生的关键层 。
2. 句子级归因分数 ($s _ {sent}^l$) 对于整句幻觉,归因分数是句子中所有词元归因分数的加权和 :
$$s _ {sent}^l = \sum _ {y_t \in T _ {sent}} w(y_t|T _ {sent}) \cdot s _ {tok}^l$$
由于句子中不同词元对幻觉的引发作用不同,作者设计了三个指标来分配权重 $w(y_t|T _ {sent})$ :
- 提示词指标:如果是句号或总结性词汇(容易触发幻觉),权重增加 。
- 位置指标:在句子中越靠后的词元,越容易产生幻觉,权重增加 。
- 幻觉指标:如果该词元本身就被标记为包含事实错误,权重显著增加 。
逐层特征引导
在计算出每一层与幻觉的相关性(归因分数 $s^l$)之后,LTS-FS 采用了一种结合了硬稀疏化 (Hard Sparsification) 和 软权重 (Soft Weighting) 的策略来调整特征 。
- 硬稀疏化(决定“改不改”): 设定一个阈值 $\tau$(由超参数 $r_s$ 控制)。如果某层的归因分数 $s^l < \tau$,说明该层与幻觉基本无关。系统会生成一个掩码 $m_l = 0$,完全不对该层进行干预,从而保护模型原本的通用能力 。
- 软权重(决定“改多少”): 对于归因分数大于阈值的层(即 $m_l = 1$),系统会计算一个归一化的相对分数 $\tilde{s}^l$ 。最终施加在这层的特征引导强度 $\lambda_l$ 会根据这个分数进行缩放 。得分越高的层,受到的引导强度越大,从而实现对幻觉“病灶”的精准打击 。
实验
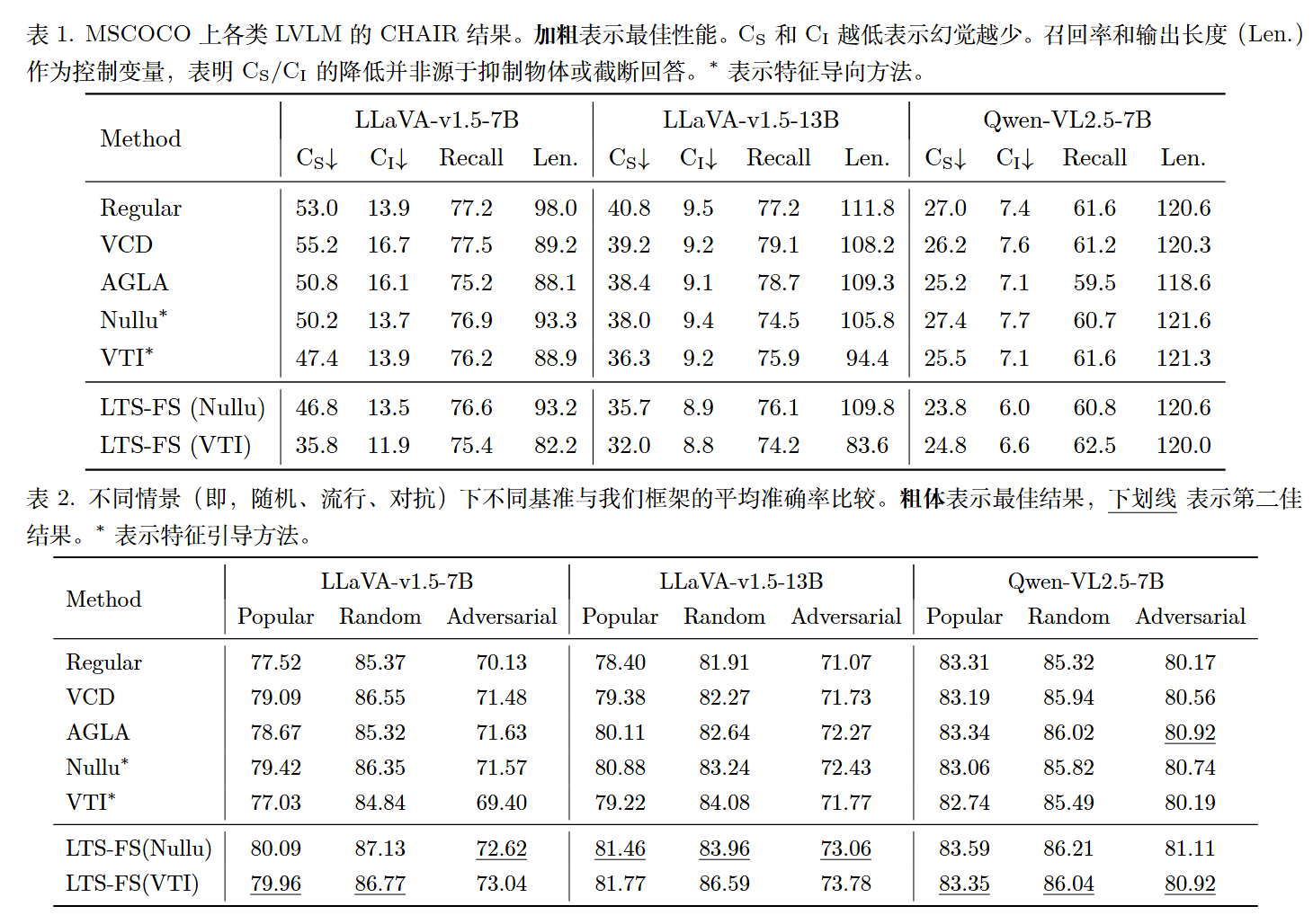
题外话
这篇论文让我看到了新方向,即我们并不需要硬磕Steering方法的核心,比如像这篇论文是研究steering的位置。这样我们就不需要重构VTI、nullu的代码,而VTI、Nullu的方法是不统一的——是重构统一困难的。