Attention MoA
(arxiv 2026)
美团 LongCat Interaction 出品
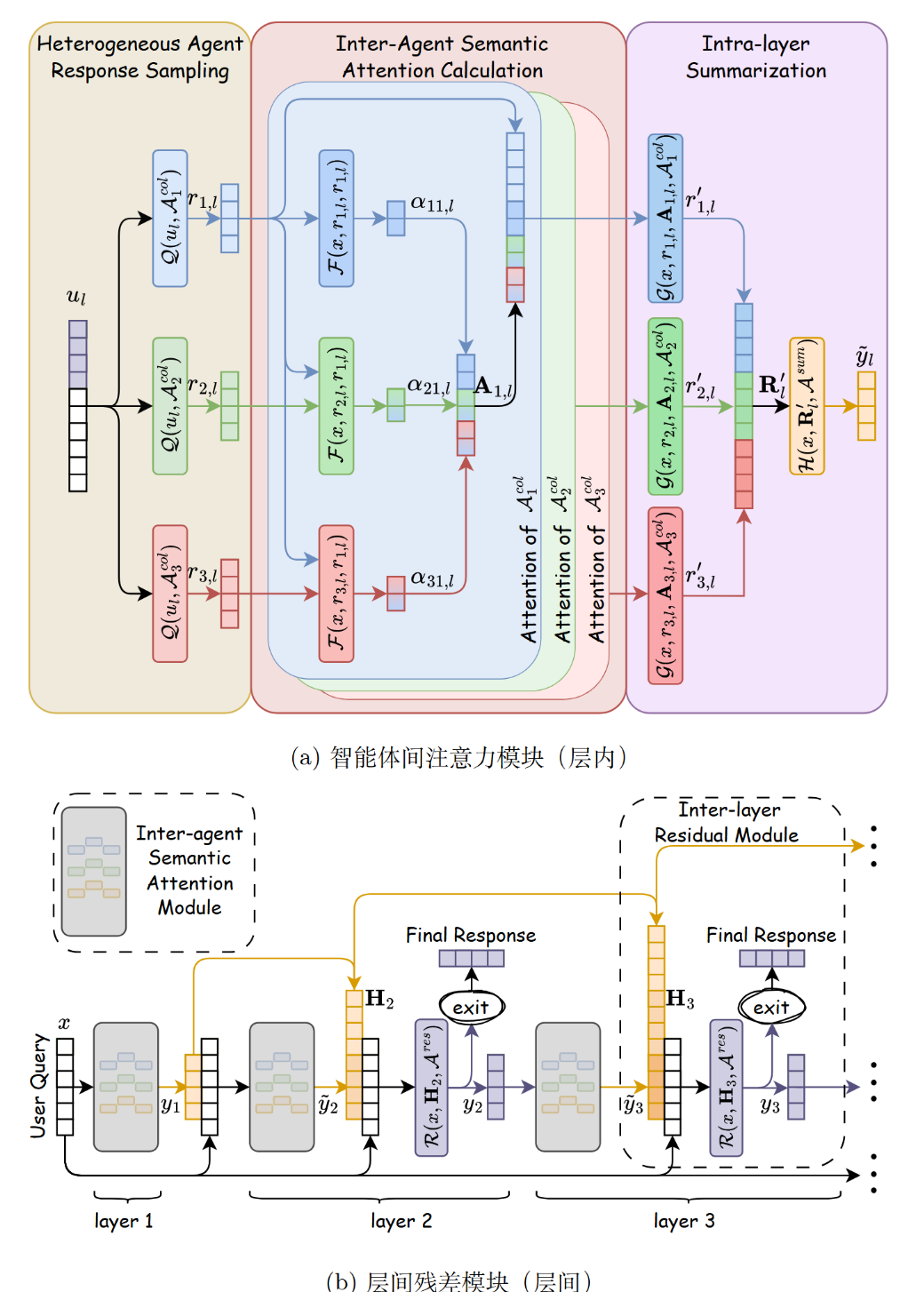
传统的 MoA (Mixture-of-Agents)框架通常只是简单地将不同模型的输出拼接在一起,缺乏深度的语义交流 。这种方式无法促使代理主动纠正彼此的逻辑错误 。同时,随着协作网络层数的加深,还会导致信息退化和计算资源的巨大浪费 。
1 | |
实验
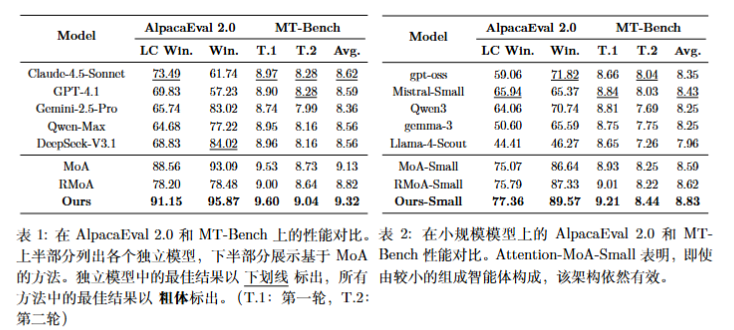
- 大规模配置:该设置采用先进的大型语言模型作为协作智能体:Claude-4.5-Sonnet Anthropic (2025),
Gemini-2.5-Pro Comanici et al. (2025),GPT-4.1 OpenAI (2025),Qwen-Max Team (2025),以及
DeepSeek-V3.1 Liu et al. (2024)。对于层内摘要智能体和残差合成智能体,我们采用 Claude-4.5-
Sonnet。 - 小规模配置:该设置在较小且高效的模型上测试框架:Mistral-Small-3.2-24B-Instruct-2506 Rastogi
et al. (2025),Qwen3-32B Yang et al. (2025a),gemma-3-12b-it Team et al. (2025),Llama-4-Scout-
17B-16E-Instruct Meta (2025),以及 gpt-oss-20b Agarwal et al. (2025)。其中,gpt-oss-20b 作为聚
合智能体。
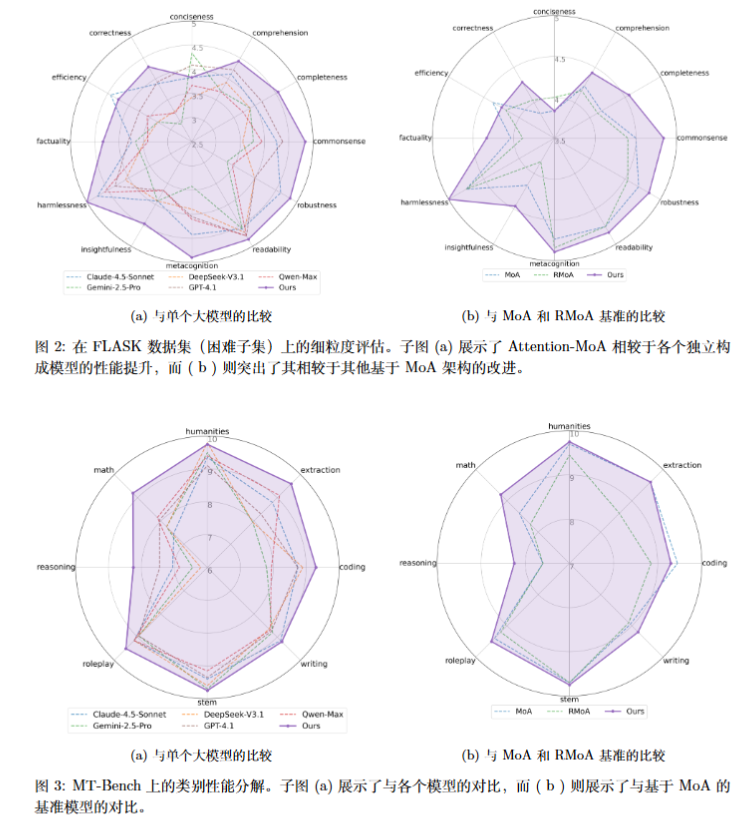
对于简洁性(conciseness)和效率(efficiency)落后于claude-4.5-sonnet和标准MoA。
是注意力-MoA 架构的预期结果:通过整合多种视角以最大化信息密度,模型倾向于生成更全面、更详细的回应,这自然会影响基于简洁性的得分。
Attention MoA
https://lijianxiong.space/2026/20260323/