DynHD: Hallucination Detection for Diffusion Large Language Models via Denoising Dynamics Deviation Learnig
(arxiv 2026)
motivation
现有的幻觉检测方法大多为 AR-LLMs 设计,无法直接应用于 D-LLMs,原因在于两者生成机制的根本差异 。D-LLMs 通过多步迭代去噪生成固定长度的序列,这意味着识别幻觉的关键证据分布在整个去噪轨迹中,而不是仅仅集中在最后一步的输出中 。
针对 D-LLMs 的早期检测方法(如 TraceDet)存在两个主要缺陷:
- 空间维度的信息密度不平衡:D-LLMs 会生成固定长度的序列,其中大部分 token 只是为了维持长度而存在的结构性填充或中间猜测,包含极少的幻觉信号 。简单地汇总所有 token 的不确定性,会使真正的幻觉信号被大量无信息的 token 淹没 。
- 时间维度的去噪动态被忽略:现有方法通常只挑选几个关键步骤进行预测,忽略了不确定性在整个扩散过程中的连续演变趋势(即去噪动态),而这种动态轨迹对于区分事实与幻觉至关重要 。
方法
前置概念
扩散语言模型(D-LLMs)的去噪过程是从完全掩码状态(第 $T$ 步)逐步推断到最终输出(第 $0$ 步)。在每一步 $t$,模型会为位置 $i$ 上的 token 预测一个概率分布 $\pi_i^{(t)}$ 。
DynHD 使用信息熵 (Entropy) 来量化每个 token 的预测不确定性 :
$$s _ {t,i} = -\sum _ {v\in\mathcal{V}} \pi_i^{(t)}(v) \log \pi_i^{(t)}(v)$$
在整个去噪过程结束后,会得到一个完整的原始不确定性轨迹 $\mathcal{T} = (\mathcal{S}_T, \mathcal{S} _ {T-1}, …, \mathcal{S}_0)$ 。
语义感知证据构建
D-LLMs 生成的是固定长度的序列,其中充斥着大量无意义的填充符和结构性 token 。直接使用原始轨迹 $\mathcal{T}$ 会引入极大噪音。
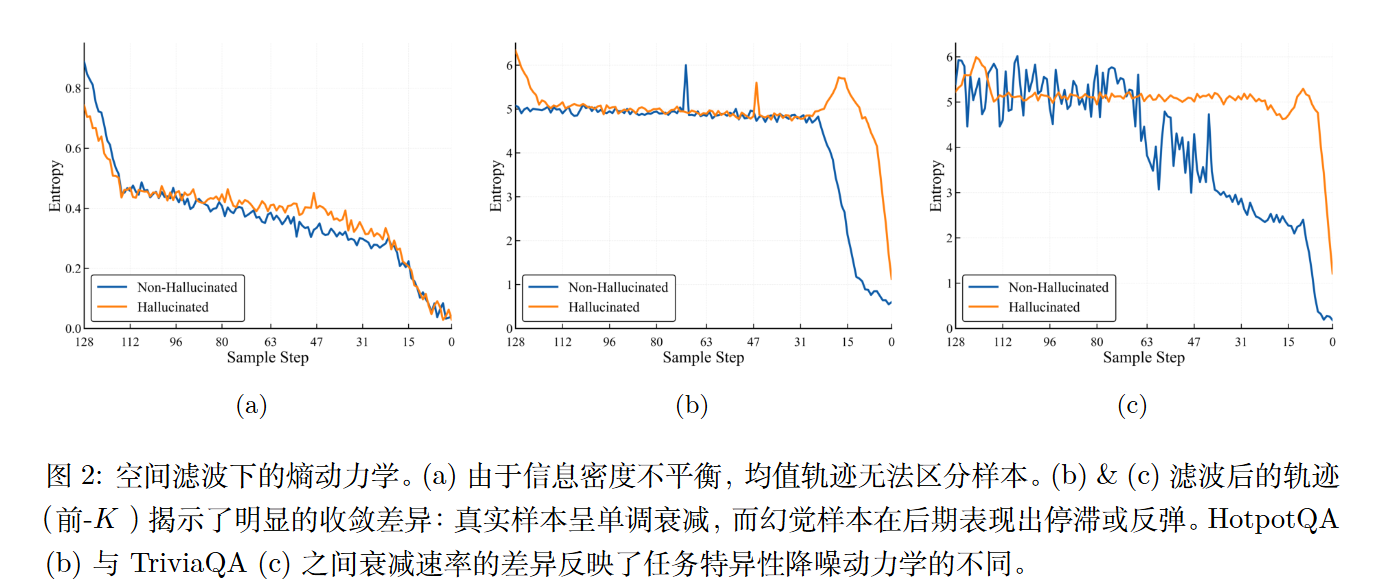
1. 语义感知 Token 过滤
模型首先定义了一个忽略集合 $\mathcal{I} _ {ignore}$(包含标点、控制标记、停用词等)。在第 $t$ 步,过滤后保留的有效语义 token 索引集合记为 $K_t$ :
$$K_t = {i \mid 1 \le i \le l, x_i^{(t)} \notin \mathcal{I} _ {ignore}}$$
2. 统计证据构建
为了防止简单的求均值操作掩盖了局部的强烈幻觉信号,DynHD 计算了三个统计量来将集合 $K_t$ 中的熵压缩为一个三维证据向量 $a_t \in \mathbb{R}^3$ :
$$a_t = [\mu _ {avg}^{(t)}, s _ {max}^{(t)}, \mu _ {top-k}^{(t)}]$$
- $\mu _ {avg}^{(t)}$: 全局不确定性(均值),反映宏观的收敛状态 。
- $s _ {max}^{(t)}$: 峰值不确定性(最大值),捕捉微观的事实错误(如生成了错误的实体名称) 。
- $\mu _ {top-k}^{(t)}$: 区域不确定性(Top-k 均值),反映短语级别的局部不确定性 。
通过将每一步的 $a_t$ 堆叠起来,原始的庞大轨迹被压缩为紧凑的语义证据轨迹 $\mathcal{E} = (a_T, a _ {T-1}, …, a_0)$ 。
动态偏差学习
得到证据轨迹 $\mathcal{E}$ 后,模型并不直接用它进行分类,而是通过学习正常去噪过程的“预期动态”,然后通过对比偏差来识别幻觉 。
1. 参考证据动态生成器 (Reference Evidence Dynamics Generator)
对于不同的提问,正常的熵演变曲线是不同的。模型引入了一个生成器 $g_\theta$,以问题特征 $q$ 和时间步 $e_t$ 为条件,预测该问题下的“理想”去噪轨迹 $\hat{a}_t$ :
$$\hat{a}t = g\theta(q, e_t)$$
该生成器仅使用真实无幻觉的样本 ($y=0$) 进行预训练 ,其损失函数为:
$$\mathcal{L} _ {ref} = \mathbb{E} _ {y=0}\left[\frac{1}{T}\sum _ {t=0}^T \text{SmoothL1}(a_t, \hat{a}_t)\right]$$
这使得 $\hat{a}_t$ 始终代表该问题下“正常的、事实正确的”基准线 。
2. 基于偏差的幻觉检测器 (Deviation-based Hallucination Detector)
检测器通过测量实际轨迹 $a_t$ 和参考轨迹 $\hat{a}_t$ 之间的差异进行预测。 首先,在每个时间步构建一个复合特征向量 $x_t$,不仅包含状态,还包含向下一步演变的速度 (Velocity) $\Delta a_t = a _ {t-1} - a_t$ :
$$x_t = [a_t; \hat{a}_t; \Delta a_t]$$
使用 MLP $f_\phi$ 将其映射为隐藏表示 $z_t$ 后,由于不同时间步对检测幻觉的重要性不同(通常后期的权重更大),模型引入了时间注意力权重 $\omega_t$ :
$$u_t = w^\top \tanh(Uz_t + b_u)$$
最终的幻觉预测 $\tilde{y}$ 是所有时间步加权求和后的结果:$\tilde{y} = \text{MLP}(\sum _ {t=0}^T \omega_t z_t)$ 。
3. 正则化损失 (Regularization Losses)
为了让模型对幻觉的两大典型特征(演变停滞和不确定性反弹)更加敏感,作者设计了两个动态惩罚项 :
路径偏差得分 (Path-deviation Score):量化累计的整体偏离程度(对应停滞)。
$$s _ {path} = \sum _ {t=0}^T \omega_t \sum _ {d=1}^D |a _ {t,d} - \hat{a} _ {t,d}|$$
反弹得分 (Rebound Score):捕捉在去噪降维过程($T \rightarrow 0$)中,本该下降的熵却突然升高的异常现象 。
$$s _ {reb} = \sum _ {t=1}^T \omega_t \sum _ {d=1}^D (\max(0, a _ {t-1,d} - a _ {t,d}))^2$$
利用滑动平均(EMA)在真实样本中计算出合理的边界(Margin)$\hat{m}$ 后,使用 Hinge Loss 来强制事实样本低于这个边界,同时将幻觉样本推离出边界 :
$$\mathcal{L} _ {hinge}(s; \hat{m}) = (1-y)\cdot s + y\cdot \max(0, \hat{m}-s)$$
最终,检测器的整体优化目标是基础分类损失 $\mathcal{L} _ {cls}$ 与这两项正则化损失的组合 :
$$\mathcal{L} = \mathcal{L} _ {cls} + \lambda_1\mathcal{L} _ {path} + \lambda_2\mathcal{L} _ {reb}$$