Vision Transformers Need More Than Registers
(CVPR 2026)
motivation
在各种预训练范式(如全监督、CLIP文本监督、DINO自监督)中,ViT 都展现出了强大的图像分类能力,但在需要“密集特征(Dense features)”的下游任务(如目标检测、语义分割)中,却普遍存在特征不对齐或“伪影”问题 。
例如,全监督 ViT 存在注意力缺失 ;文本监督的 CLIP 模型无法产生与文本精确对齐的密集图像特征 ;自监督模型 DINOv2 在特征图上会产生极高范数的“High-norm tokens”,从而破坏目标定位任务 。
之前的研究(如为 DINO 引入 Register tokens)只是将这些异常高范数的 token 转移到了额外的寄存器中,这种“治标不治本”的方法并未能完全解决下游任务中的底层缺陷 。作者认为,高范数 token 只是模型在训练中后期表现出的症状,并非问题的根本原因 。
这些伪影源于一种“懒惰聚合”(lazy aggregation)行为:ViT 在全局注意力机制和粗粒度语义监督的驱动下,利用语义无关的背景图像块作为捷径来表征全局语义。
发现
为了统一量化不同监督模式下的伪影问题,作者提出了两个新的探针(指标):
- Patch Score(图块得分):计算每个 Patch 特征与代表全局语义的 CLS token 之间的余弦相似度 。
- Point-in-Box (PiB):评估得分最高的 Patch 是否真实落在前景目标的边界框内 。
通过这两个探针,作者得出了一个重要假设和结论:
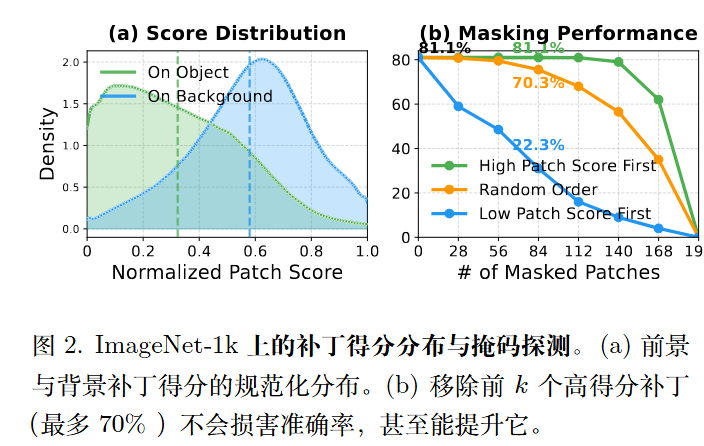
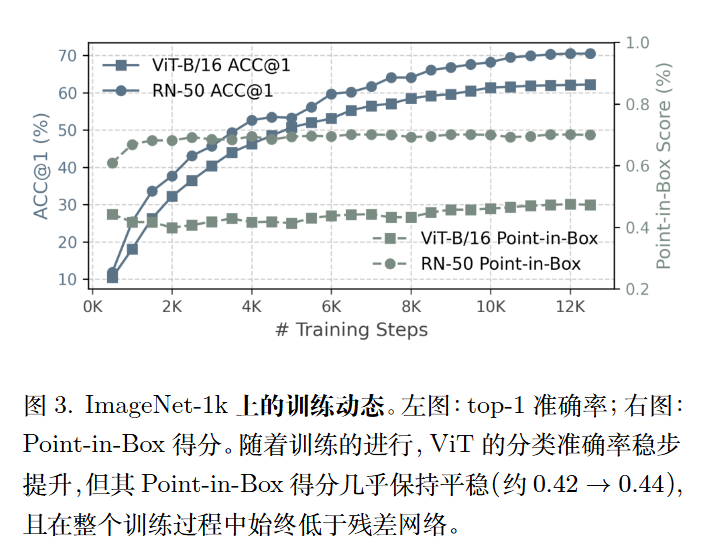
- 背景主导偏差:作者发现,无论是哪种预训练方法,ViT 的高 Patch Score 往往集中在无意义的背景区域(如天空、草地),而非前景物体上 。与 ResNet 等卷积网络相比,ViT 的 PiB 得分要低得多 。
- 懒惰聚合行为(Lazy Aggregation):这是导致伪影的根本原因 。由于自然图像中包含大量背景,ViT 在训练初期就会寻找“捷径”,将少量的前景语义扩散到大量的背景 tokens 中去 。
- 两大诱因:这种捷径行为是由粗粒度语义监督(只给图像级别的标签,缺乏空间级指导)和全局依赖性(全局自注意力机制使得特征可以随意扩散)共同驱动的。
方法
限制背景 Patch 对 CLS token 的影响,迫使模型将注意力重新锚定在前景语义上 。在自然图像中,前景信号的语义含义往往更加单一,其在深层特征通道维度上的变化较小(低频);而背景通常具有更高的语义多样性(高频) 。因此,作者利用一维快速傅里叶变换(FFT1D)和低通滤波,计算每个 Patch 在通道维度上的“稳定性得分” 。
首先,进行频域低通滤波。将 ViT 编码器输出的所有 Patch 特征(不包含 CLS token)表示为 $x _ {patch} \in \mathbb{R}^{N \times D}$,其中 $N$ 是 Patch 的数量,$D$ 是通道维度 。 为了提取低频稳定信号,作者在通道维度上对每个Patch 进行了 1D 傅里叶变换(FFT1D),并应用高斯权重 $g \in [0, 1]^D$ 进行低通滤波,然后再通过逆傅里叶变换(IFFT1D)还原回空间域。
$$x _ {FFT} = FFT1D(x _ {patch})$$
$$x _ {LP} = x _ {FFT} \odot g$$
$$\hat{x} _ {patch} = \mathfrak{R}{IFFT1D(x _ {LP})}$$
其中,$\odot$ 表示逐元素相乘,$\mathfrak{R}{\cdot}$ 表示提取复数的实部,最终得到的 $\hat{x} _ {patch}$ 就是经过低通滤波后的平滑特征 。
为了衡量每个 Patch 在特定通道上的稳定性,作者比较了滤波后的特征和原始特征。通道级的稳定性得分 $S _ {i,j}$ 用于评估第 $i$ 个 Patch 的第 $j$ 个通道在经过低通滤波后保留了多少信息(即受高频噪声影响的程度) 。
然后是,通道级 Top-K 选择性聚合 (Channel-wise Top-K Pooling)。
这是 LazyStrike 的核心机制,取代了传统的全局平均池化(GAP)或全局自注意力机制。 既然已经得到了每个 Patch 在每个通道上的稳定性得分 $S _ {i,j}$,LaSt-ViT 在构建最终的 CLS token(即全局表示 $Q _ {CLS}$)时,不再盲目融合所有 Patch,而是在每个通道 $j$ 上独立操作,只挑选最稳定的前 $K$ 个 Patch 进行平均聚合 。
数学表达如下:
获取第 $j$ 个通道上得分最高的 $K$ 个 Patch 的索引集合 $\mathcal{I}_K(j)$:
$$\mathcal{I} _ {K}(j) = TopK({S _ {i,j}} _ {i=1}^{N}, K)$$
计算 CLS token 的第 $j$ 个通道的值(即对这 $K$ 个特征求均值):
$$Q _ {CLS}[j] = \frac{1}{K} \sum _ {i \in \mathcal{I} _ {K}(j)} x _ {patch}[i,j]$$
通过这一步,CLS token 的每一维特征都只来源于该维度上最稳定的那部分(极大概率是前景)Patch 。
另外,为了验证上述方法是否真的选中了前景,作者还定义了一个“投票数(Vote Count)”指标,用于计算某个 Patch $i$ 在所有 $D$ 个通道的聚合过程中,总共被选中了多少次 。
$$v_i = \sum _ {j=1}^{D} 1{i \in \mathcal{I} _ {K}(j)}$$