DYNAMIC MULTIMODAL ACTIVATION STEERING FOR HALLUCINATION MITIGATION IN LARGE VISION-LANGUAGE MODELS
(ICLR 2026)
发现
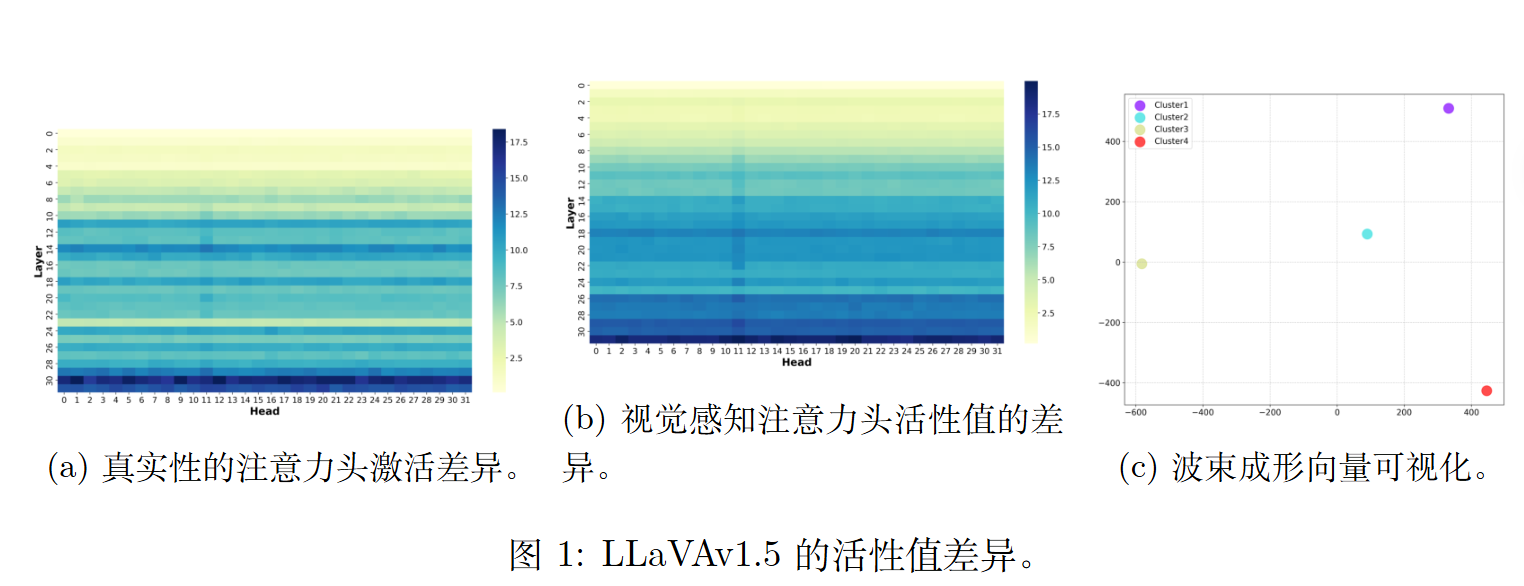
注意力头分工不同:控制模型“真实性(Truthfulness)”和“视觉感知(Visual Perception)”能力的注意力头在模型架构中大多属于不同的子集。
语义语境的影响:控制真实性的引导向量在不同的语义上下文中存在显著差异 。这意味着固定不变的静态干预方法无法适应不同输入的语义变化。
方法
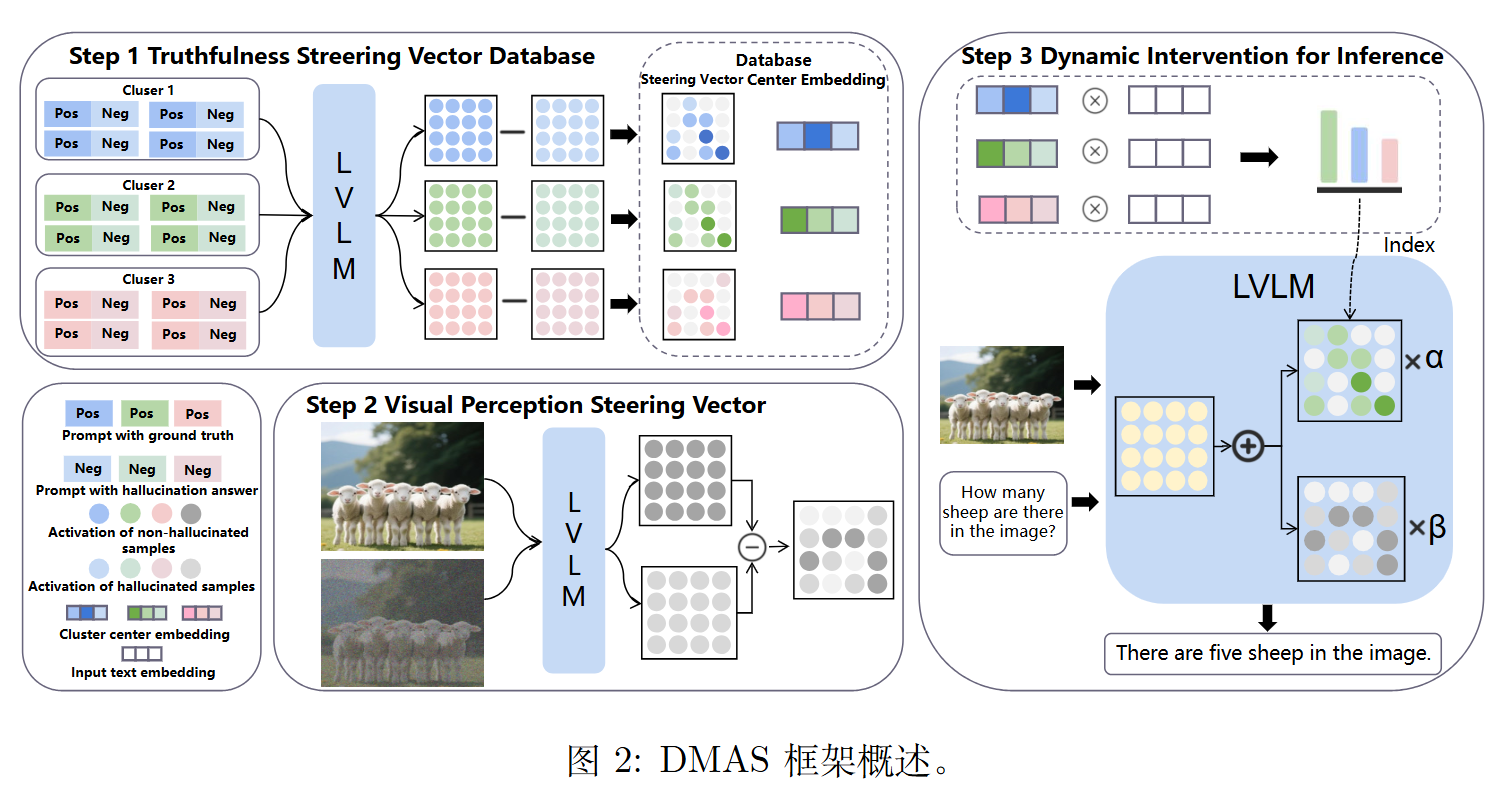
引导向量
同先前的文献一样,它也会分为视觉引导向量和语义引导向量。
对于语义引导向量,会分为四个簇。(论文使用的是tsne)
对于第 $i$ 个语义簇 $C_i$,引导向量 $D_i$ 定义为:
$$D_i = \frac{1}{|C_i|}\sum _ {j\in C_i}(A _ {pos,j}-A _ {neg,j})$$
- $|C_i|$ 代表该聚类中的样本数量。
- $A _ {pos}$ 和 $A _ {neg}$ 分别是输入正样本(含真实答案)和负样本(含幻觉答案)时,模型在特定层的注意力头激活值。
对于视觉引导向量,为VCD高斯噪声那一套。
$$D_v = A_v - A _ {v’}$$
其中
$A_v$ 是模型处理正常清晰图像时的激活值 。
$A _ {v’}$ 是模型处理添加了扩散噪声的失真图像时的激活值 。
同时地,会对两种引导向量应用PCA。
有四个簇,故有四个引导向量,但是不会全用。先判断当前问题属于哪个话题,然后去数据库里把对应的“真实性纠偏向量”拿出来。
$$D_f = D _ {\hat{i}}, \text{ where } \hat{i} = \arg\max \text{sim}(E(T), \text{Key}_i)$$
$E(T)$ 是当前输入文本的嵌入表示(Embedding) 。
$\text{Key}_i$ 是数据库中第 $i$ 个聚类的中心表示 。
$\text{sim}(\cdot,\cdot)$ 是余弦相似度函数,用来寻找最匹配的那个引导向量 $D_f$ 。
过滤与掩码
模型不修改模型所有的注意力头,因为有可能会把模型原有的正常能力改坏。故只挑出对“真实性”和“视觉”影响最大的前 $K$ 个头进行干预 。
$$M _ {\{f,v\}} ^ {(l,h)} = \begin{cases} 1, & \text{if } (l,h) \in \text{TopK}(D _ {\{f,v\}}, K) \ 0, & \text{otherwise} \end{cases}$$
- $(l,h)$ 代表第 $l$ 层的第 $h$ 个注意力头。
- 如果该头属于激活差异最大的前 $K$ 个,掩码设为 1(允许干预);否则设为 0(保持原样)。
干预
$$x ^ {(l+1)} = x ^ {(l)} + \text{Concat} _ {(0\sim H)} [\text{Attn} ^ {(l,h)}(x ^ {(l)}) + \alpha \cdot M _ f ^ {(l,h)} \cdot D_f ^ {(l,h)} + \beta \cdot M_v ^ {(l,h)} \cdot D_v ^ {(l,h)}] \cdot W_o ^ {(l)}$$
- $x ^ {(l)}$ 是第 $l$ 层的隐藏状态(原本的特征流)。
- $\text{Attn} ^ {(l,h)}(x ^ {(l)})$ 是正常的自注意力计算结果。
- $\alpha$ 是控制“真实性”强度的超参数。
- $\beta$ 是控制“视觉感知”强度的超参数。